EDIT: I have YARA rules available for this one, if you need them, contact me at contact@robin-dost.de Also, checkout my project KRAKEN if you’re interested in continuous threat actor tracking.
Lately I’ve been spending more time looking at malware targeting Ukraine and Europe. And yeah, a lot of it is neither new nor particularly creative. But it works. And that’s exactly why it’s worth digging into.
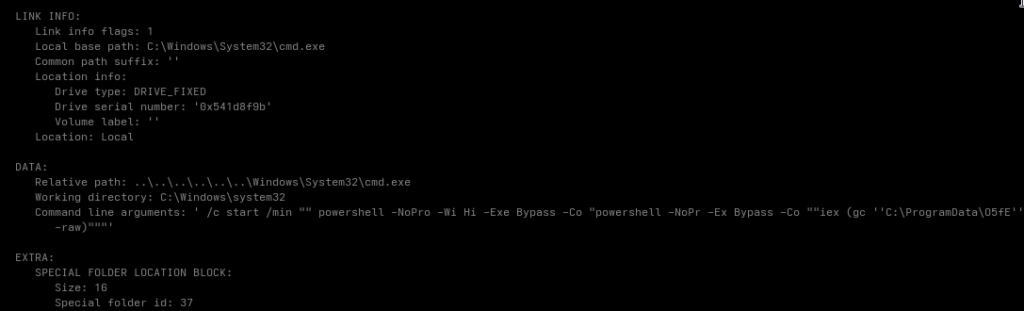
The sample we’re looking at here is fresh (from today, 09.04.2026), part of a UAC-0226 campaign and turns out to be a variant of the well-known GIFTEDCROOK stealer.
Initial access? Surprise: CVE-2025-6218 & CVE-2025-8088. Maybe you already know this one from one of my previous articles. A prepared archive, some basic social engineering, an LNK and the user still clicks it. End of story.
From there it’s the usual flow:
LNK launches payload Payload decodes another binary Binary initially looks like absolute garbage
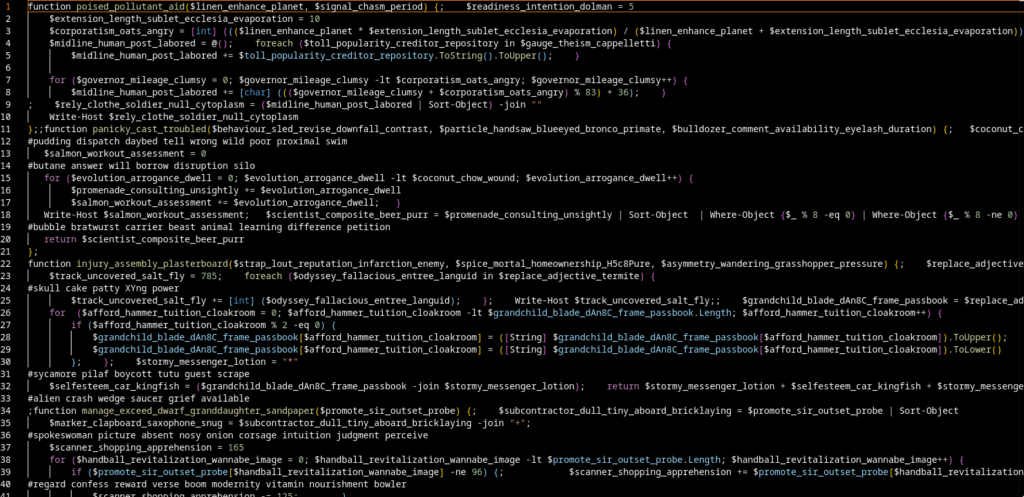
Constants everywhere, useless function calls, pseudo-random noise. The classic “maybe the analyst just gives up” approach.
If you ignore all that noise, what’s actually happening becomes pretty obvious:
RC4-based encryption
Chunked data exfiltration
A simple but working exfil client
Runtime reconstructed C2
Nothing high-end. No fancy exploit chain fireworks. Just cleanly glued together building blocks doing exactly what they’re supposed to do: grab data and ship it home.
And that’s exactly what makes this sample interesting.
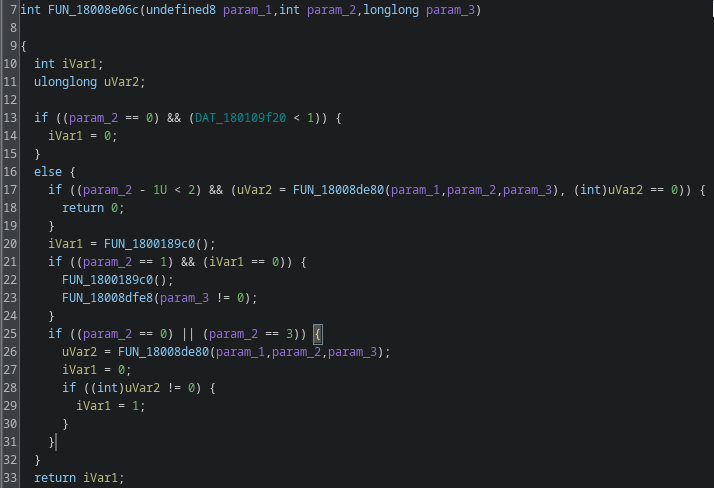
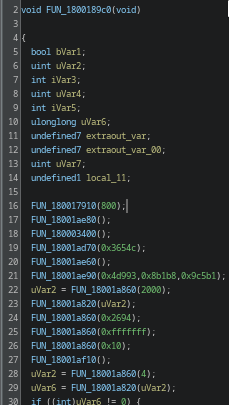
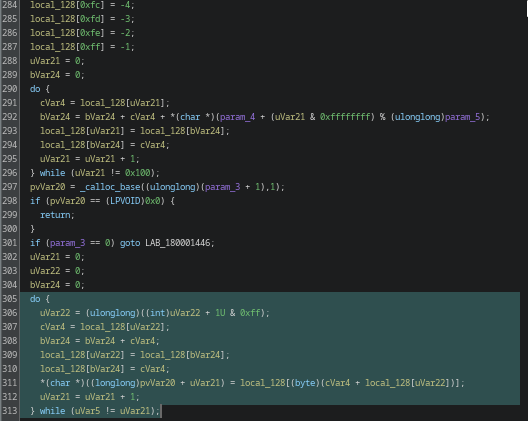
This looks like a main dispatcher. Function FUN_1800189c0 stands out immediately.
The function is full of junk and noise with only a few real control paths hidden inside. After going through it, a couple of functions are actually relevant. FUN_180001180
It sets up a 256-byte state array (S-box) using the provided key. The algorithm starts with a simple identity permutation (0–255) and then shuffles it based on the key through a series of swaps. The process mixes the key material into the internal state, effectively “seeding” the cipher.
Once KSA is complete, the resulting permutation is used by the PRGA (Pseudo-Random Generation Algorithm) to produce the keystream that will later be XORed with the data
The malware is a GIFTEDCROOK stealer variant used by UAC-0226.
Who is UAC-0226?
UAC-0226 is basically a designation used by Ukrainian CERT for a Russian-aligned threat actor group primarily targeting Ukraine. Some of the artifacts and the tradecraft found currently and in the past make me also believe that this is a russian (speaking) threat actor, but that’s just me. Their tradecraft is pretty straightforward “it works, so we use it” operations: a lot of phishing, archives, LNKs, then multi-stage payload chains.
Classic flow is: user clicks something > loader > next stage > eventually you end up with a stealer like GIFTEDCROOK.
What makes this interesting:
They don’t build ultra complex frameworks. They build simple chains that are just obfuscated enough (RC4, some string garbage, staged decoding) to make analysis annoying, even if this one wasn’t exactly a masterpiece.
It’s not elegant, but effective enough and that’s exactly what makes them relevant for us 🙂
As already mentioned in my last MuddyWater article, I originally planned to take a closer look at the remaining RustyWater samples in the hope of finding additional leftover artefacts. But: writing a pure “let’s grep a few more binaries for leftovers” follow-up article sounded painfully boring, both to read and to write. So instead of doing that, I decided to version the individual samples properly and build a small change-tracking timeline around them.
Mostly out of curiosity, partly out of stubbornness. At least this way we get something that resembles actual analysis rather than archaeological string hunting.
Before diving into version diffs and timelines, it’s worth briefly grounding what we’re actually dealing with here, without turning this into a full-blown reverse engineering novella.
RustyStealer (sometimes referenced as RustyWater, Archer RAT or related variants in public reporting) is a Rust-based information stealer / RAT that has been observed in MuddyWater-attributed campaigns. In practice it behaves like a fairly typical post-compromise implant: basic host reconnaissance, security product awareness, persistence via registry, C2 communication and modular task execution. Nothing magical, nothing revolutionary, just a modernized tooling stack implemented in Rust instead of the usual C/C++ ecosystem. Here’s an article from cloudseek.com if you are interested in the details of it’s deliver and execution nature.
And that’s exactly where this article deliberately does not go: this is not a line-by-line teardown of every decoding routine, syscall wrapper or math loop. There are already reports on the internet that lovingly explain how a single function increments a counter.
What I’m interested in instead is how this thing evolves over time and how to track it
How do the binaries change between builds? Which libs appear or disappear? When does the architecture shift? Where do experiments get rolled back? Which parts get hardened, obfuscated or simplified?
The goal is to treat this malware family more like a software project with a messy commit history than a static artifact. By correlating compile timestamps, dependency fingerprints, fuzzy hashes, embedded artefacts and targeted code diffs, we can reconstruct a surprisingly coherent development timeline and extract signals about tooling maturity, experimentation phases and operational priorities .
And honestly: that’s way more fun than grepping strings all day and more useful for my threat actor research
My First Step: I always start with the most low-effort signal: raw strings. Sometimes you get lucky and developers leave behind absolute paths, usernames, toolchain artefacts or other accidental breadcrumbs.
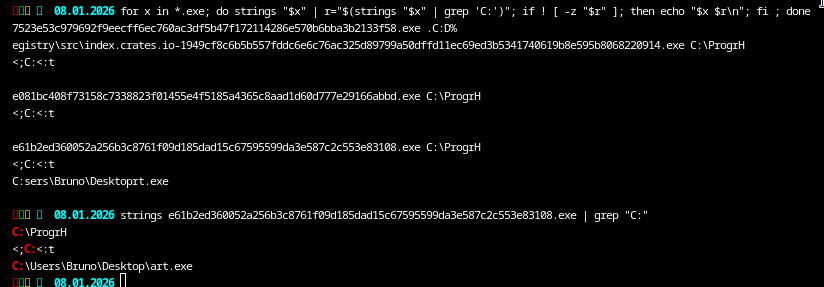
The first thing I wanted to verify was whether any additional user paths were embedded in the samples:
for x in *.exe; do strings "$x" | r="$(strings "$x" | grep 'C:')"; if ! [ -z "$r" ]; then echo "$x $r\n"; fi ; done
And yes, in two of the binaries we do indeed find another leftover artefact:
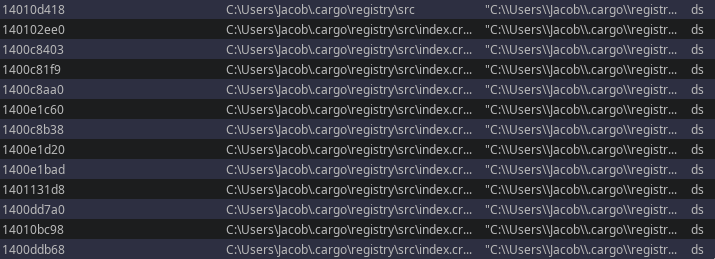
C:\Users\Bruno\Desktop\art.exe
C:\Users\Jacob\...
Just to be clear: the developer is almost certainly not named Bruno/Jacob. This is simply the username of the build environment used at that time. Still, it gives us a nice anchor point when correlating samples later on.
Dependency extraction and library fingerprinting:
Next, I wanted to extract the dependency information from the binaries:
# get llvm strings
for x in *.exe; do strings "$x" | r="$(strings "$x" | grep 'llvm')"; if ! [ -z "$r" ]; then echo "$x $r\n"; fi ; done
# get crates with version and write to file sample.exe.strings
for x in *.exe; do strings "$x" | grep "crates\.io-" | cut -d'\' -f5 | sort | uniq >> "$x.strings" ; done
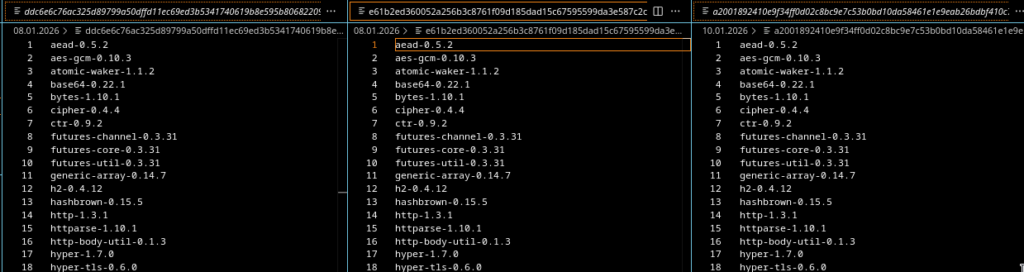
This gives us a list of Rust crates and libraries that were present at build time:
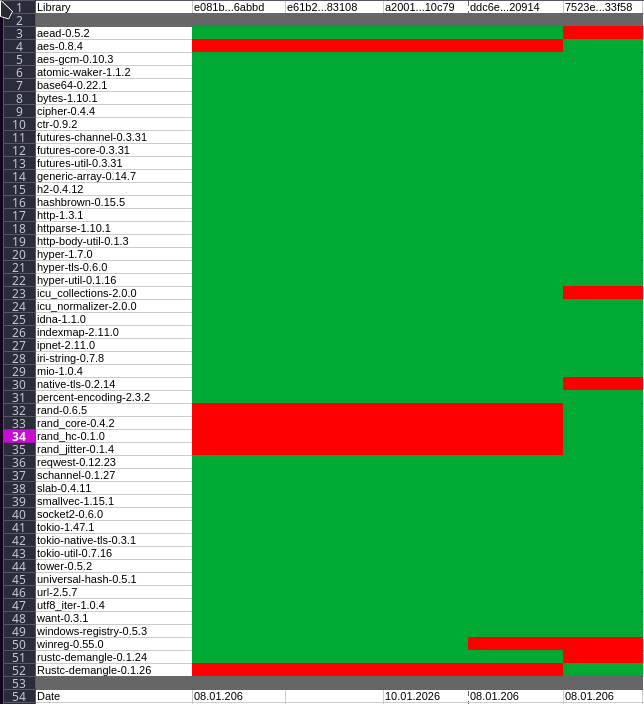
From this output I consolidated a full list of all dependencies observed across all samples. It already allows a first sanity check: are all samples built from the same dependency set or do we see deviations?
In total, the consolidated list contains 50 libraries, however, each individual sample only exposes around 44-45 crates. That already tells us that not all builds are identical.
Here is the full list of observed libraries:
Library
Version
aead
0.5.2
aes
0.8.4
aes-gcm
0.10.3
atomic-waker
1.1.2
base64
0.22.1
bytes
1.10.1
cipher
0.4.4
ctr
0.9.2
futures-channel
0.3.31
futures-core
0.3.31
futures-util
0.3.31
generic-array
0.14.7
h2
0.4.12
hashbrown
0.15.5
http
1.3.1
httpparse
1.10.1
http-body-util
1.7.0
hyper
1.7.0
hyper-tls
0.6.0
hyper-utils
0.1.16
icu_collections
2.0.0
icu_normalizer
2.0.0
idna
1.1.10
indexmap
2.11.0
ipnet
2.11.0
iri-string
0.7.8
mio
1.0.4
native-tls
0.2.14
percent-encoding
2.3.2
rand
0.6.5
rand_core
0.4.2
rand_hc
0.1.0
rand_jitter
0.1.4
reqwest
0.12.23
schannel
0.1.27
slab
0.4.11
smallvec
1.15.1
socket2
0.6.0
tokio
1.47.1
tokio-native-tls
0.3.1
tokio-util
0.7.16
tower
0.5.2
universal-hash
0.5.1
url
2.5.7
utf8_iter
1.0.4
want
0.3.1
windows-registry
0.5.3
winreg
0.55.0
rustc-demangle
0.1.24
rustc-demangle
0.1.26
Since we now know that differences exist, I built a per-sample matrix to visualize which libraries appear in which binary:
This makes deviations immediately visible without having to manually diff text dumps.
Compile timestamps
Before grouping anything, I also checked when the individual binaries were compiled.
This can be extracted using:
for x in *.exe; do printf "$x"; objdump -x "$x" | grep "Time/Date"; don
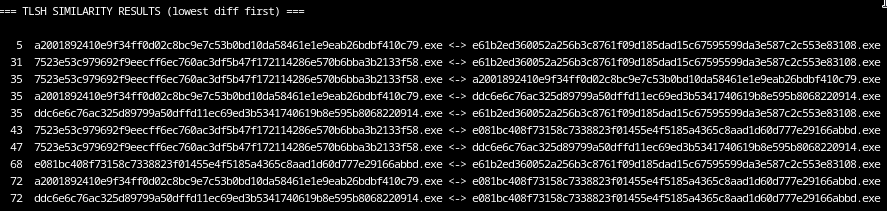
As a final preprocessing step I generated TLSH hashes for all samples.
TLSH is a fuzzy hashing algorithm that does not aim for exact equality, but instead quantifies structural similarity between files. Unlike cryptographic hashes, TLSH allows us to estimate how closely two binaries resemble each other internally even if they differ in resources, padding, timestamps or small code changes.
For our malware analysis purpose, this is especially useful when clustering variants, detecting rebuilds and separating development branches.
To make the distances reproducible, I wrote a small script that computes TLSH values directly from the binaries and performs pairwise comparisons:
Clustering the samples
With all of this data available, we can now perform a reasonably robust clustering of the samples
The key point here is that no single metric is deciding on its own. Instead, the correlation of multiple independent signals matters:
TLSH similarity
Compile timestamps
Library fingerprints
Embedded user artefacts
Cluster 1: Core codebase
The first cluster represents the actual core of the codebase and contains the samples:
All three share identical lib dependencies and are compiled close together in time, two of them even share the exact same compile timestamp. One sample also contains the user artefact "Bruno", which further hints to a consistent build environment.
Despite moderate TLSH distance to some variants, the internal similarity inside this cluster remains high enough to confidently assume a shared codebase.
Cluster 2: Early feature branch
A second, clearly separable cluster consists solely of:
This sample extends the otherwise stable library stack with an additional winreg dependency while remaining TLSH-close to the core samples. Combined with its earlier compile timestamp, i think this a temporary feature branch or experiment rather than a fully independent development line.
The build differs by multiple additional libraries and introduces a newer version of rustc-demangle. Additionally, a different username ("Jacob") appears in the artefacts. While the TLSH distance still places this sample within the same family, it consistently sits outside the tighter core cluster range. Taken together, this strongly indicates a later development branch with an updated toolchain and likely expanded functionality
Overall, this results in a three-tier model:
A stable core cluster forming the technical baseline
An early feature branch with minimal extension
A later modernization branch with a changed toolchain and build environment
My clustering is not driven by hash similarity alone, but only becomes reliable through the combined temporal, structural and artefact based corelation. It also provides insight into development practices, build discipline and potential role separation within the development process of the malware
Version mapping
Based on this clustering, I derived the following version mapping:
At this point we already have a solid structural overview without having touched the actual code yet. This part comes next.
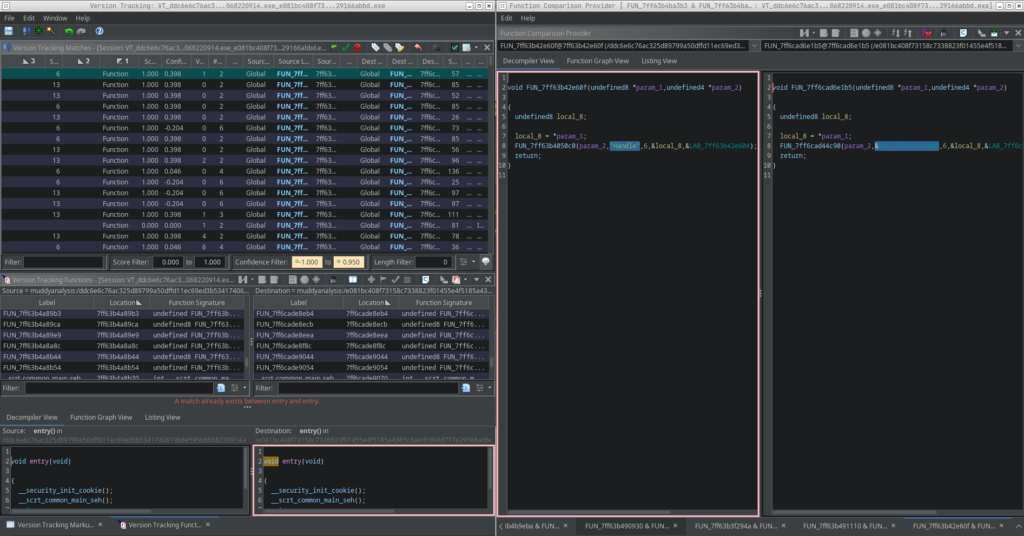
For the code comparison I use Ghidras Version Tracking module. The versions will be analyzed in the following pairs:
v0.9 <-> v1.0
v1.0 <-> v1.1
v1.1 <-> v2.0
So three comparisons in total which honestly is still a very manageable workload
Let’s get started 🙂
Version Tracking workflow
I won’t go into a full tutorial on how Ghidras Version Tracking works. Instead, I’ll briefly outline my simple workflow for today.
First, I set the confidence filter to:
-1.0 -> 0.950
Everything above that can usually be assumed identical across samples. I select all those findings and accept them in bulk.
For the remaining findings, I set up a small quality-of-life shortcut:
SHIFT + T = Assign Tag
Then I filter the results by:
Tag (ascending)
Type (ascending)
Status (ascending)
and tighten the confidence filter slightly to:
-1.0 → 0.95
This gives me a clean view of all unresolved function-level differences without assigned tags, exactly the changes that matter most when identifying structural evolution.
It looks roughly like this:
The workflow is simple:
Select the next finding
Open code comparison (SHIFT + C)
If identical -> accept (SHIFT + A)
If different -> assign a tag for later analysis (SHIFT + T)
Once accepted or tagged, the finding disappears from the filtered view and I repeat the process.
I iterate this until all relevant changes are reviewed and documented.
RustyStealer: Evolution from v0.9 to v2.0
What changed, what failed and what the developer learned
During a longitudinal analysis of multiple RustyStealer builds, four development stages become visible for me: an early baseline version (v0.9), a cleanup iteration (v1.0), a short-lived performance refactor (v1.1) and a more fundamental architectural shift in v2.0.
Rather than showing linear feature growth, the samples show a realistic iterative engineering process with experimentation, rollback and eventual consolidation toward stealth and reliability.
This analysis focuses on behavioral deltas inferred from import-level changes and binary artifacts.
Version 0.9: Early baseline and rough edges
The earliest observed build (v0.9) represents a relatively raw implementation.
Notable characteristics:
Dependency artifacts included unused crates such as winreg / windows-registry ( i guess early experimentation or leftover scaffolding)
No meaningful behavioral differences compared to later v1.0 builds
No advanced memory manipulation or cryptographic primitives observed
Limited internal abstraction and minimal architectural complexity
From a development POV, v0.9 looks like a staging build that still contained residual dependencies and experimental code paths that were not yet cleaned up.
Version 1.0: Cleanup and stabilization
The transition from v0.9 to v1.0 did not introduce meaningful functional changes. The most visible difference was the removal of unused dependency artifacts (such as the winreg crate) without any observable change in imports or runtime behavior.
This looks more like a dependency cleanup rather than a behavioral refactor
Key observations:
No changes in imported Windows APIs
No observable change in capabilities or execution flow
Binary differences consistent with rebuild noise and dependency graph cleanup
This phase reflects basic project hygiene rather than feature development.
Version 1.1: Performance experiment and internal refactor
Version 1.1 marks the first technically ambitious change
Major changes observed:
Introduction of asynchronous and overlapped file I/O:
Migration to modern Windows path resolution via SHGetKnownFolderPath.
Explicit memory cleanup for shell APIs using CoTaskMemFree.
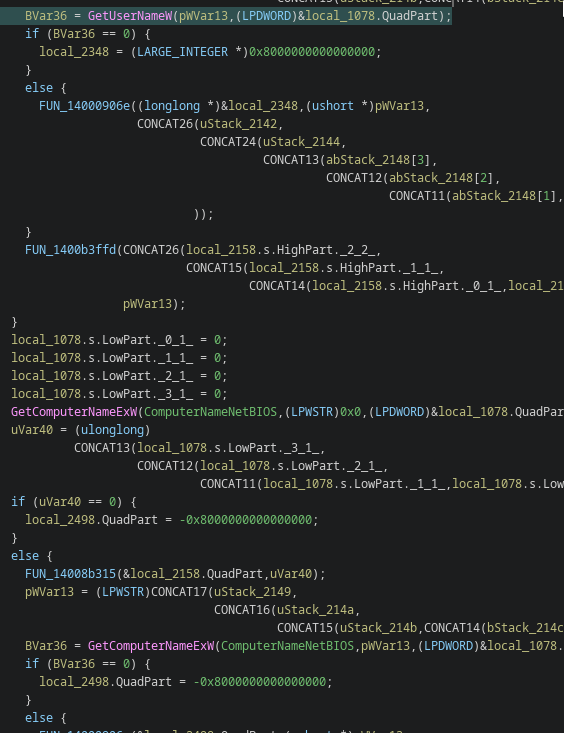
Removal of host fingerprinting:
GetComputerNameExW
GetUserNameW
NetGetJoinInformation
This version appears to have attempted:
Faster and more scalable file harvesting.
Cleaner filesystem abstraction.
Reduced behavioral noise by temporarily disabling host profiling.
However, asynchronous I/O pipelines significantly increase complexity and often cause instability in realworld environments This version looks more like a technical experiment rather than a long term production design for me
Additional findings from later code diffs
Looking at later builds and comparing them back to this branch reveals several important follow-up changes that appear to originate from the 1.1 refactor.
String handling and Defender artefacts
Older builds still expose cleartext strings such as direct Windows Defender directory paths, making static detection trivial. In later builds these strings disappear entirely and are reconstructed at runtime using multiple XOR-based decoding routines and different key constants.
I believe the outcome of the 1.1 refactor was the realization that static strings were becoming a liability, leading to systematic runtime string decryption in subsequent versions.
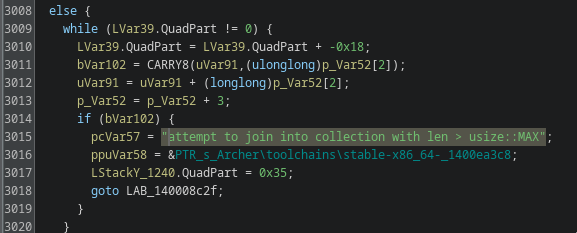
Collection handling and stability
Later builds include additional safety checks when aggregating dynamic collections (explicit overflow protection when joining result sets) The same logic exists in earlier builds but is less defensive and less structured.
This points to stability issues encountered when processing larger data sets, which maybe were discovered during or shortly after the scalability experiments introduced in version 1.1.
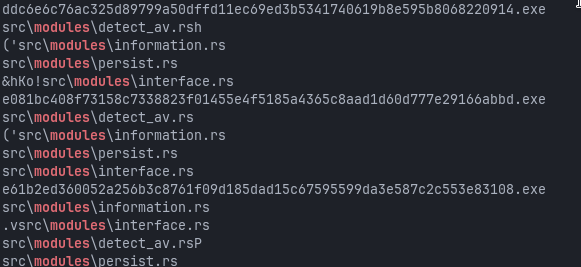
Modular architecture continuity
Both older and newer builds continue to reference internal Rust modules such as:
src\modules\persist.rs
src\modules\interface.rs
src\modules\information.rs
src\modules\detect_av.rs
It confirms that the internal refactor in 1.1 successfully established a modular layout that later versions could iterate on without further structural changes.
Toolchain and build artefacts
Later samples expose more Rust toolchain artefacts (stable-x86_64 paths and related metadata) and show noticeable hash divergence despite similar functionality. This looks like a change in compiler version or build environment after this refactor phase, which may also explain subtle behavioral and binary layout differences between closely related samples.
My take
Version 1.1 looks like the point where the developers started stress testing their own architecture.
They might have pushed performance and concurrency, simplified some noisy host profiling and cleaned up API usage. The follow-up changes visible in later diffs show that this experiment exposed two main pain points:
Static strings and predictable artefacts were too easy to signature.
Increased scale and concurrency exposed stability issues in collection handling.
Instead of doubling down on complex async I/O, later versions appear to focus more on obfuscation, robustness and operational reliability, while keeping the modular structure introduced here.
imo 1.1 feels less like a production release and more like a learning phase that shaped the technical direction of everything that followed.
Version 2.0: Architectural consolidation and stealth optimization
Version 2.0 represents a clear update in development priorities.
Instead of further expanding the async pipeline, the developer reverted many of the experimental components and focused on stealth, operational control and internal maturity.
Major changes observed:
Removal of asynchronous file pipeline
All overlapped I/O and event-based sync primitives present in v1.1 have been fully removed in v2.0 and later builds. No replacement async scheduling mechanisms (IOCP, APCs, worker pools or deferred execution patterns) are observable in the call graph.
The runtime execution flow is now strictly sequential, with simplified synchronization primitives replacing the earlier concurrency model. It looks like the experimental async pipeline was abandoned in favor of a more predictable and operationally stable execution model. It reduces architectural complexity, lowers race condition risk and improves long-term stability across victim environments. All overlapped I/O and event-based synchronization APIs were removed, indicating that the v1.1 experiment was abandoned in favor of a simpler and more predictable execution model.
Reintroduction of host fingerprinting
Host identification APIs returned:
GetComputerNameExW
GetUserNameW
NetGetJoinInformation
Focus on victim profiling, campaign correlation and backend attribution logic The temporary removal in v1.1 now appears to have been an experimental privacy / noise reduction phase rather than a permanent design direction.
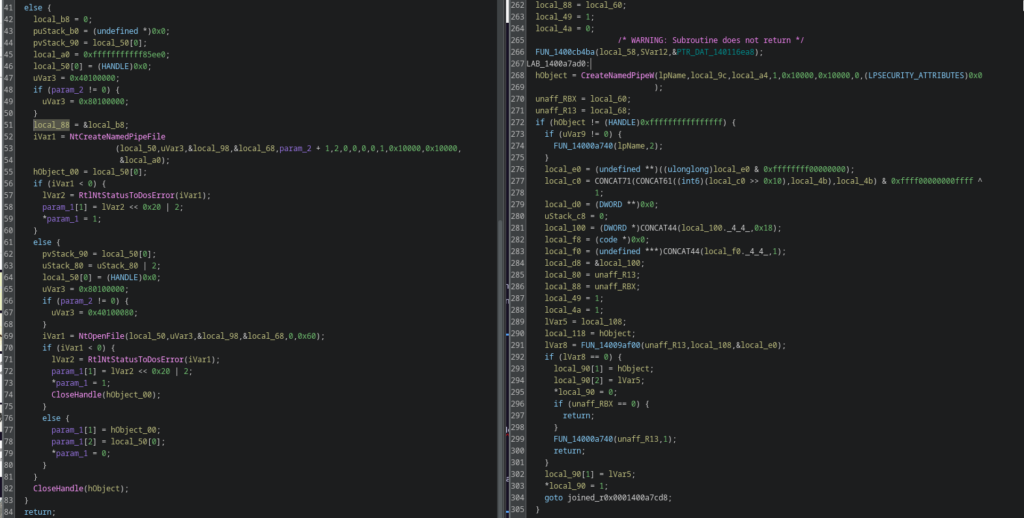
Migration towards native NT APIs
Several subsystems were migrated towards native system calls:
Named pipes moved from CreateNamedPipeW to NtCreateNamedPipeFile
File handling introduced NtOpenFile
This reduces visibility to user-mode API hooking and increases resistance against common EDR userland instrumentation.
Introduction of cryptographic randomness and entropy hardening
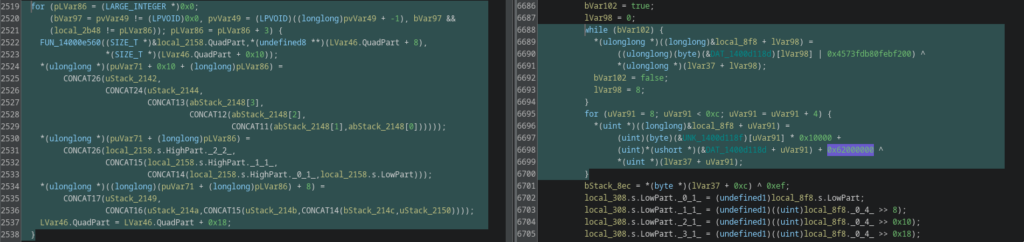
Version 2.0 introduces a dedicated entropy generation pipeline based on SystemFunction036 (RtlGenRandom), replacing the previously implicit and largely deterministic behavior.
Rather than simply requesting random bytes, the implementation builds a full entropy pool that combines cryptographically secure randomness with adaptive jitter-based sampling and internal quality validation. The generated entropy is statistically evaluated at runtime and rejected if it fails basic stability and distribution thresholds. Only entropy that passes these health checks is propagated further into the execution flow.
The call chain shows that the generated randomness directly feeds into subsequent runtime decoding routines, where multiple obfuscated data blocks are reconstructed through XOR-based transformations and dynamic key. In earlier versions, these decode paths relied almost entirely on static constants and predictable transformations. In v2.0, parts of this process become entropy-dependent and therefore non-deterministic across executions
From an operational perspective this has several implications:
Runtime decoding behavior becomes less reproducible for static analysis and sandbox instrumentation.
Signature-based detection and clustering become more fragile, as internal state and derived values differ per execution.
Correlation across samples using hash similarity, instruction-level signatures or deterministic unpacking pipelines becomes significantly harder.
The malware gains a higher degree of resilience against emulation environments with weak or manipulated entropy sources.
While the mechanism could theoretically support use cases such as object naming, session identifiers or cryptographic material, the integration into the decode pipeline indicates more that the primary motivation is obfuscation hardening and stealth rather than feature expansion
It marks a shift in development priorities: the developers invest in making existing functionality harder to observe, reproduce and classify
Memory protection manipulation (VirtualProtect)
VirtualProtect appears in v2.0, but not as a generic “unpacking” indicator.
It is used to flip a read-only dispatch table to writable just long enough to store dynamically resolved API pointers, then lock it back down. Thats consistent with the shift towards runtime API resolving and NT-level calls: fewer static imports, less signature surface and a resolver layer that is harder to tamper with or trivial hook
Internal synchronization refactor
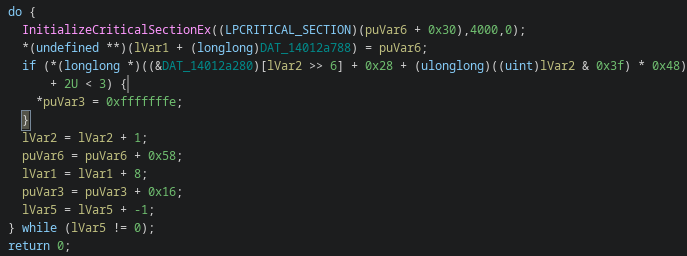
Thread state handling was refactored away from TLS primitives and migrated towards modern synchronization APIs (InitializeCriticalSectionEx)
I think it’s for architectural cleanup and improved concurrency control.
Obfuscation hardening and decoder abstraction
Compared to version 1.1, version 2.0 further abstracts string decryption and reconstruction logic. Previously visible XOR decoders with fixed constants and static data offsets were refactored into more generic reconstruction helpers and indirect decode routines.
This significantly reduces static signature stability and increases the effort required for automated clustering and YARA-style detection.
Improved memory lifecycle management and cleanup paths
Version 2.0 introduces more explicit cleanup sequences, callback-based destructors and tighter buffer lifecycle handling.
Multiple teardown paths now explicitly free dynamically allocated buffers, invoke destructor callbacks and normalize internal state after large collection operations. It might be an effort to reduce memory leaks, crash probability and long-running instability during high-volume data processing.
Build pipeline evolution
Build artifacts show a different Rust toolchain and build environment compared to version 1.1. Toolchain paths shifted from shared “Archer” layouts towards user-local rustup environments, explaining observed TLSH divergence despite largely stable runtime behavior.
This reflects internal “”””build pipeline”””” changes rather than functional malware changes.
Summary
Version 2.0 prioritizes:
Simplification and rollback of risky experimental I/O designs
Stronger stealth via native API usage and obfuscation hardening
Improved runtime stability and memory hygiene
Reintroduction of host profiling for operational correlation
Internal architectural consolidation rather than feature expansion
Overall, this release reflects a stabilization phase where operational reliability and detection resistance outweigh rapid feature development
Conclusion
If there’s one takeaway from this exercise, it’s that even relatively “boring” commodity implants become surprisingly interesting once you stop treating them as static blobs and start treating them like evolving software projects.
By correlating build artefacts, dependency drift, fuzzy hashes and targeted code diffs, we can reconstruct a fairly coherent development timeline for RustyStealer without having to reverse every single function into oblivion. We see experimentation phases (hello async pipeline), rollbacks when ideas don’t survive real-world friction, hardening towards stealth (dynamic API resolution, entropy injection) and the usual toolchain churn that comes with real developers shipping real code, even if that code happens to be malware. None of this magically turns RustyStealer into some nextgen cyber superweapon. It’s still fundamentally a fairly standard implant doing fairly standard implant things. Also it’s a nice reminder that “grep strings > extract a few IOCs > call it a day” only gets you so far. If you actually want to understand how an actor operates, what they experiment with and where their engineering effort goes, you have to look at trends, not snapshots. Which admittedly takes more time, more coffee and slightly more patience than copy-pasting hashes into VirusTotal buuuut the payoff is a much clearer picture of what’s really going on under the hood.
There’s also a more general lesson in all of this imo
If the goal is to actually understand a threat actor, not just label a sample and move on, then obsessing over individual functions, opcodes and micro-optimizations only gets you part of the way. That level of detail is useful, but it doesnt tell you how the tooling evolves, where engineering effort is invested, which ideas get abandoned or how operational priorities shift over time. These signals live in the truly boring parts: build artefacts, dependency drift, architectural refactors, version churn and the occasional accidental breadcrumb left behind in a binary or wherever. When you line those up over multiple samples, you start seeing intent and process instead of isolated behaviour and this exactly what we want ^-^
Since I want to dive deeper into reverse engineering, I’ve decided to regularly solve CrackMe challenges from https://crackmes.one; I’ll begin with low-difficulty ones and gradually work my way up to harder challenges.
I chose this approach because it’s a practical way to build and demonstrate the fundamentals, reverse engineering can be overwhelming at first, so starting with simpler tasks helps establish a reliable foundation.
Because this is a fairly simple exercise, I’ll analyze it with radare2 instead of Ghidra, partly to avoid making the task trivial and I’ll concentrate on how to translate assembly into readable pseudo-C code step by step. I recommend gaining a basic understanding of Assembly and the C programming language before diving in. I’ll keep this write-up as beginner-friendly as possible and have included links to resources that explain any terminology that might be unfamiliar to newcomers, if you have any questions, feel free to contact me.
If you want to dive deeper into radare2 commands, i recommend reading it’s official documentation or the following cheatsheet. Here is a list of references for research used in this WriteUp:
After downloading the binary, the first thing I’ll do is launch radare2 with the -A option to run an automatic analysis pass.
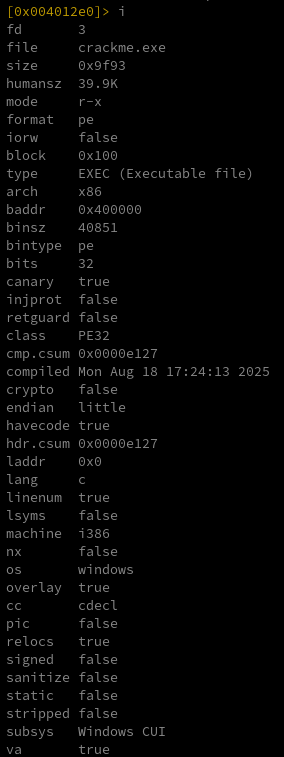
Once radare2 has loaded the binary, you can type i to display detailed information about the loaded excutable.
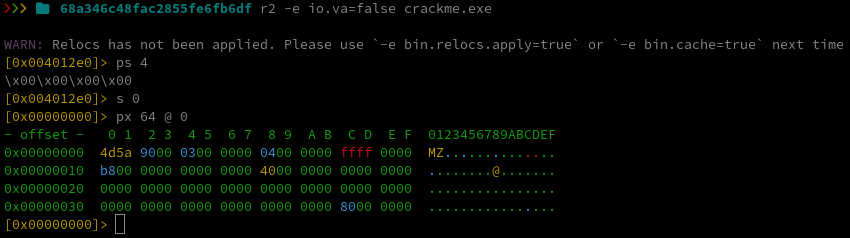
The binary is a Windows Portable Executable (PE) file. A Portable Executable file is a format used for executable and object files in Windows operating systems, based on the Common Object File Format (COFF). It’s used for files such as .exe, .dll, .sys, and others. The structure begins with a 64-byte MS-DOS header starting with the characters “MZ” (0x5A4D) and includes an offset field (e_lfanew) that points to the actual PE header. In PE files, it’s important to distinguish between file offsets (positions in the raw file) and virtual addresses (VA), which are used once the file is loaded into memory. In radare2, s 0 moves to the file offset 0x0, while s baddr jumps to the binary’s base virtual address (usually 0x00400000 for Windows executables).
You can inspect the e_lfanew field with:
pv4 @ 0x3c
This gives the offset to the PE header. If the result is 0xffffffff, it typically means the memory region isn’t mapped or is filled with placeholder bytes (0xFF).
We can also verify this by entering the following command:
s 0
# Shows the MS-DOS header ("MZ ...")
px 64 @ 0
As expected, you can see the “MZ” signature (0x4D5A) at the beginning of the header. PE files (like all Windows binaries) use little-endian byte order, meaning the least significant byte comes first. In radare2:
px 4 @ 0x3c ; shows raw bytes (in little-endian order)
pv4 @ 0x3c ; interprets those 4 bytes as a 32-bit integer
You can also use pf to parse structured data, for example:
pf 2s e_magic; 58x; 4u e_lfanew @ 0
This reads the e_magic signature and the e_lfanew offset in one step, making PE header inspection much clearer.
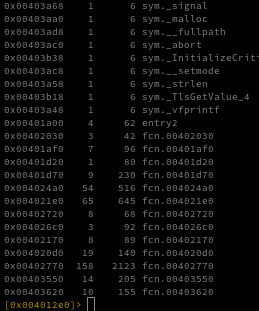
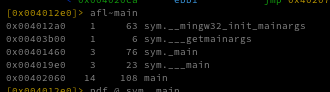
Now I’ll run afl to list the functions that radare2 discovered in this binary. The list is extensive, but we’re specifically looking for the entry function where the executable begins execution.
The entry function is located at 0x00401a00; radare2 has already taken us there automatically, but you can jump to it manually with s 0x00401a00.
Using afl~main we can list all functions whose names include “main.”
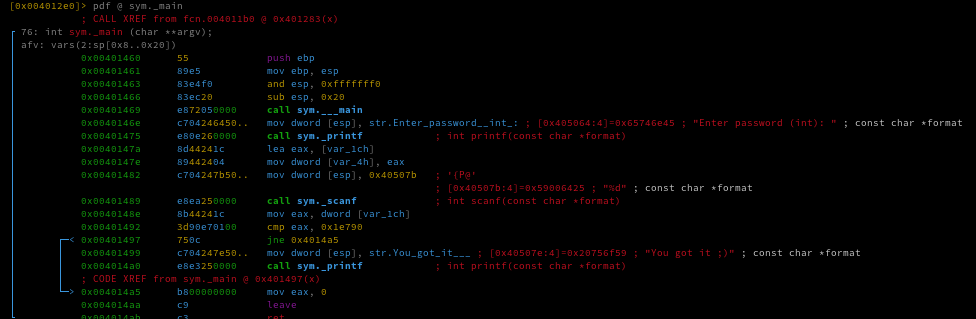
To display the assembly code for this function, I can use the command pdf @ sym._main.
Now we can translate the given assembly into pseudocode to better visualize what the function is doing. I’ll start by deriving the function signature (parameters and return type). Here’s the general approach:
fastcall: the first arguments are passed in ecx and edx
Count the number of arguments
For stdcall: the number of arguments = imm in ret imm / 4
For cdecl:
Count the push instructions (or mov [esp+…]) before the call in the caller function
Example: three push instructions -> three arguments
If the callee references its arguments directly:
[ebp+8] -> first argument
[ebp+0xC] -> second argument, and so on.
Determine the return type Check the final instructions in the function body:
Used as an address -> pointer
Value returned in eax (32-bit) -> int, bool, or pointer
Value returned in edx:eax -> 64-bit integer
Value returned via st0 (FPU) -> float or double (common with fld/fstp)
(SSE returns on x86-32 are rare; on x64 they use xmm0.)
Consider semantics:
Only 0 or 1 -> likely bool
Multiple values or error codes -> int
Now, for our specific case:
Since the callee doesn’t use any parameters in its data flow, we move to its caller (the CRT startup routine). In PE/MinGW, the startup sequence typically goes like this: mainCRTStartup -> __tmainCRTStartup -> ___main or __mingw32_init_mainargs -> _main(argc, argv, envp)
Identifiying CRT vs. User Code:
When analyzing Windows executables, you’ll often see functions like ___main, mainCRTStartup, or __tmainCRTStartup. These belong to the C Runtime (CRT)and handle setup tasks such as initializing global variables, the floating-point environment, and calling your actual main function. A quick rule of thumb: if the function name starts with multiple underscores or manipulates environment or FPU state (fldenv, fninit, ldmxcsr), it’s part of the CRT, not user-written code.
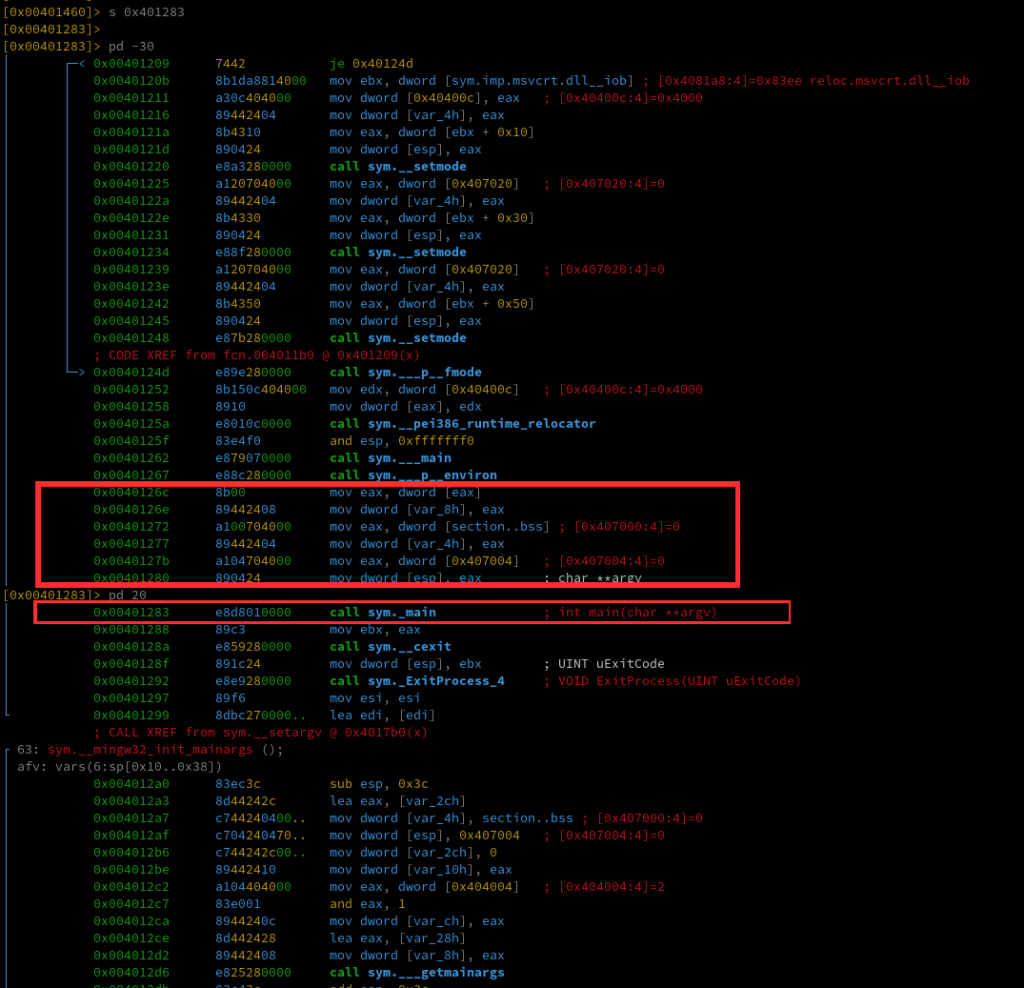
We can now inspect the call sites in radare2. Looking at the initial disassembly output, we can identify the relevant line:
; CALL XREF from fcn.004011b0 @ 0x401283(x)
This shows the address of the call site. We can jump to that address and review the instructions leading up to the call with:
s 0x401283
pd -30
pd 20
Here we can see the typical behavior of the C runtime (CRT), which retrieves the arguments from global variables and passes them to main using a push-less call convention.
Push-less Call Convention? What is that? (CLICK)
Some compilers (like GCC or MinGW) don’t use the traditional push instructions for function arguments. Instead, they write the argument directly onto the stack with mov [esp], value and then call the function. When the call instruction executes, it automatically pushes the return address, which shifts the argument down to [esp+4]exactly where the callee expects it according to the cdecl calling convention.
Example:
mov [esp], 0x405064 ; write argument (string address)
call printf ; CPU pushes return address -> arg at [esp+4]
This technique saves instructions and is known as a push-less call setup.
Here’s a brief explanation of the assembly code: ___p__environ() returns a pointer to the global variable environ, which is of type char***. mov eax, [eax] dereferences it once, so eax now holds a char** the actual envp pointer. This value is then stored in var_8h, effectively setting envp = environ;.
[0x407000] is a CRT global variable, typically representing __argc. Therefore, var_4h receives the value of argc, effectively making it argc = __argc;.
[0x407004] is the CRT global variable for __argv, which is of type char**. mov [esp], eax writes the first function argument directly onto the top of the stack without using a push instruction. This is a common compiler pattern known as a “push-less call setup,” meaning argv is now prepared as the first parameter for the upcoming function call.
The call uses exactly what’s currently stored in [esp], which is argv. That’s why radare2 annotates the function signature as int main(char **argv)only argv is passed as an argument.
Now that we understand how the parameter passing works, we can start writing our first pseudocode.
<RETURN-TYPE> main(char **argv) {}
We still need to determine the return type for the function signature, which should be relatively easy to identify. To do this, I’ll take a look at the final instructions of our assembly function.
mov eax, 0 gives us a clear indication of the return type. To determine it, it’s useful to look at which register is being used in the mov instruction right before the leave and ret sequence. In 32-bit code, the return value is always stored in the EAX register. This follows the ABI (Application Binary Interface) convention, which applies to all languages that adhere to C calling conventions such as C, C++, Pascal, and stdcall.
Calling Conventions? What is that? (CLICK)
Understanding the calling convention is essential when reconstructing a function’s signature. You can often identify it by looking at how the stack is cleaned up and how arguments are passed:
Convention
Stack Cleanup
Argument Passing
Typical Pattern
cdecl
Caller
via stack (push / mov [esp+..])
ret
stdcall
Callee
via stack
ret N (N = args × 4)
fastcall
Callee
first args in ecx, edx
ret N
thiscall
Callee
ecx = this (C++)
ret N
If the callee doesn’t access any arguments directly, inspect the call site instead — count how many push or mov [esp+..] instructions occur before the call. That number tells you how many parameters are passed.
Rückgabetyp (in C)
Register
Größe
int, bool, pointer
EAX
4 Bytes
float
ST0 (FPU)
4 Bytes
double
ST0 (FPU)
8 Bytes
long long
EDX:EAX
8 Bytes zusammengesetzt
We can therefore confidently conclude that the return value is an integer, allowing us to expand our pseudocode accordingly.
int main(char **argv) {}
We can therefore confidently conclude that the return value is an integer and expand our pseudocode accordingly.
Now we can finally focus on analyzing the data flow and translating it step by step.
The prologue of the function can be ignored when writing our pseudocode, it is responsible for setting up the stack frame, aligning the stack to 16 bytes, reserving local variables, and initializing the C runtime (CRT).
Stack frame? What is that? (CLICK)
At the beginning of a function, the compiler sets up what’s called a stack frame. sub esp, 0x20 reserves 32 bytes (0x20) on the stack for local variables. Each local variable is located at a specific offset relative to either esp or ebp.
Example:
esp+0x00 → return address (after the call)
esp+0x04 → first function argument
esp+0x1C → local variable var_1ch
So, lea eax, [var_1ch] loads the address of that local variable into eax, not its value.
At the end of the function, the leave instruction restores the previous stack frame, and ret pops the return address to resume execution at the caller.
The first section of code that we can meaningfully translate begins at address 0x0040146e:
esp+00 <- Here, the compiler immediately stores the first function argument (push-less).
esp+04 <- 2. Argument
...
esp+1C <- local int (radare: var_1ch)
The first section of code that we can meaningfully translate begins at address 0x0040146e:
At address 0x0040146e, the instruction writes the 32-bit value 0x405064 the address of the C string constant "Enter password (int): " stored in the .rdata section to the top of the stack ([esp]). This represents a push-less argument setup: instead of using push imm32, the compiler writes the first function argument directly into the stack slot. This pattern is typical for GCC and MinGW.
Immediately afterward, the function printf is called to print the string. During the call, the CPU automatically pushes the return address onto the stack, which decreases esp by 4 bytes.
We can now extend our pseudocode as follows:
int main(char **argv) {
printf("Enter password (int): ");
}
At address 0x0040147a, we can see that the function’s stack frame contains a local variable at offset 0x1C, var_1ch is radare2’s symbolic name for the stack slot at [esp+0x1c] (i.e., a local 0x1C bytes into the 0x20-byte frame reserved by sub esp, 0x20).
This variable is not initialized and, as we can see in the final instruction of this block, it is used as the destination for the scanf call to store the user input.
We can incorporate this information directly into our pseudocode:
int main(char **argv) {
printf("Enter password (int): ");
int input;
scanf("%d", &input);
}
Our code is slowly starting to take shape and gain some structure, so let’s move on and analyze the remaining instructions:
cmp eax, 0x1e790 compares the value in EAX (previously loaded from [var_1ch], i.e. the user-input) with the 32-bit constant 0x001E790 (decimal 124816), which is important for our CrackMe Challenge, this is effectively the flag; the CPU updates the status flags (including the Zero Flag, ZF) as a result.
Translating Comparisons and Flags into if Statements (CLICK)
The cmp instruction sets CPU status flags based on the result of a subtraction (A - B), and conditional jumps like je, jne, or jg use those flags to control flow.
Instruction
Condition (Flag)
High-Level Equivalent
je / jz
ZF = 1
if (A == B)
jne / jnz
ZF = 0
if (A != B)
jg / jnle
ZF=0 & SF=OF
if (A > B)
jl / jnge
SF≠OF
if (A < B)
Example:
cmp eax, 0x1e790
jne 0x4014a5
translates to
if (input != 124816) goto 0x4014a5;
Tip: You can quickly convert hexadecimal to decimal in radare2 with
? 0x1e790
0x00401497 jne 0x4014a5 is “jump if not equal”: it branches only when ZF == 0 (values unequal); if the input != 124816 execution jumps to 0x4014a5, skipping the subsequent print.
If EAX == 0x1E790 (ZF == 1), execution falls through to the next block: mov dword [esp], 0x40507e writes the address of the C string "You got it ;)" (located in .rdata at 0x40507e) into [esp] as the first function argument, a push-less argument setup (instead of push imm32).
call sym._printf invokes printf(const char *format); the call pushes the return address so that printf finds its first argument at [esp+4], consistent with the cdecl/varargs calling convention.
Finally, mov eax, 0 loads the immediate value 0 into EAX (overwriting any previous content); under the 32-bit cdecl ABI EAX is the standard return register, so this corresponds to return 0;. leave restores the stack frame (mov esp, ebp; pop ebp), and ret returns control to the caller.
Identifying and understanding is a Keyskill for writing Pseudocode, so
int main(char **argv) {
printf("Enter password (int): ");
int input;
scanf("%d", &input);
if (input == 124816) {
printf("You got it ;)");
}
return 0
}
With this, we now have both the flag (124816) and the pseudocode for the challenge; I hope you were able to follow along and take something useful from my write-up. If you have feedback or questions, feel free to comment or contact me.
I also recommend reviewing all linked resources, as they can be very helpful if you want to dive deeper into reverse engineering 🙂